

0
1
2
3
4
5

 ********
******** ********
********2022-09-01 -至今zjutstu
计算机视觉方向,在读研究生,复现超30个CV项目,擅长Python,C++编程,中CCF-A类会议一篇
2022-09-01 - zjut计算机科学与技术硕士
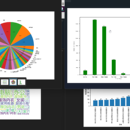
分析目标网页,找到数据所在位置。豆瓣电影Top250的网页结构很规整,数据所在DOM节点位置清晰可辨。 2. 选择爬虫工具。这里我选择了Scrapy,它是Python的一个强大的爬虫框架,可以轻松编写复杂的爬虫程序。 3. 创建Scrapy项目和Spider。使用命令`scrapy startproject douban_movie`和`scrapy genspider top250 douban.com`。 运行Spider,获取数据。使用命令`scrapy crawl top250`运行Spider,得到电影信息列表。 6. 数据存储与展示。将数据保存到CSV文件,然后使用Matplotlib绘制电影评分分布直方图,并用Pandas制作电影top10排行榜。 这个爬虫项目让我熟练掌握了Scrapy的使用,学会了解析复杂网页的技巧,并将爬取的数据进行了简单的统计分析与展示。Scrapy是一个非常强大的爬虫框架,利用它可以轻松开发各种爬虫项目。
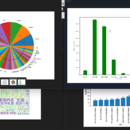
这个项目的目标是使用Python的Matplotlib和Seaborn库对一些数据集进行可视化处理和分析。例如: - 载入Iris数据集,使用Seaborn绘制iris花的分类Scatter plot - 载入傅里叶级数数据集,使用Matplotlib绘制傅里叶级数和音高的关系曲线 - 载入股票历史数据,使用Matplotlib绘制股票的走势图和成交量图 在这个项目中,我熟悉了如何使用Matplotlib和Seaborn两个强大的可视化库绘制静态和动态的信息图表。并学会了一些简单的数据分析方法。 这两个项目经历锻炼了我在Python中的图像处理、数据分析与可视化的技能。Python拥有丰富的第三方库,使用这些库可以轻松实现各种实用功能。我发现,做项目最好的方式就是想一个目标,然后去探索各种库找实现的方法。 在这个过程中不仅练手,也加深了对库的理解,收获良多。
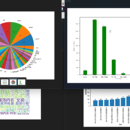
这个项目的目标是开发一个Python脚本,实现对图片进行基本处理,比如: - 图片的裁剪、缩放 - 水印添加 - 图片格式转换(jpg to png, png to jpg等) - 图片压缩 我使用了Python的图像处理库Pillow来实现这个项目。编写Python脚本,定义各个图像处理函数,通过函数的参数实现不同的处理效果。并使用argparse库解析命令行参数,实现通过命令行调用这些函数。




