

0
1
2
3
4
5

 ********
******** ********
********2018-07-01 -2024-03-21腾讯开发
网络爬虫及网站开发经验 Python多进程、多线程、协程技术 Python运行时内存优化技术 Python程序打包成exe的技术 高并发、抗反爬的网络爬虫技术(XPATH、Regex正则表达式,数据加密解密、数据提取、数据清洗、数据存储优化、验证码破解、代理池构建等) Web网站后端开发技术(Django、Flask、Mysql、Redis、Nginx、Supervisor) Mysql数据库设计及数据备份、同步、查询优化技术 Redis、MongoDB数据库使用技术 Django、Scrapy的使用技术 服务器自动化部署及定时调度技术 基于Matlab的图像加密、图像无痕水印技术网络爬虫及网站开发经验 Python多进程、多线程、协程技术 Python运行时内存优化技术 Python程序打包成exe的技术 高并发、抗反爬的网络爬虫技术(XPATH、Regex正则表达式,数据加密解密、数据提取、数据清洗、数据存储优化、验证码破解、代理池构建等) Web网站后端开发技术(Django、Flask、Mysql、Redis、Nginx、Supervisor) Mysql数据库设计及数据备份、
2014-09-01 - 2018-06-26电子科技大学电子信息硕士
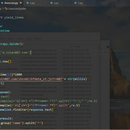
Scrapy来爬取球探网的数据:可以爬取球员数据,包括球员名称、年龄、身高、体重、位置、球队,历史比分等信息。通过浏览器开发者工具查看页面元素,确定数据位置,以便后续定位提取。使用requests获取页面:构造请求获取不同位置的球员数据页面。使用BeautifulSoup解析页面:解析页面HTML文档,使用CSS选择器或XPath提取包含目标数据的标签内容。 使用正则表达式提取数据:对提取的文本内容使用正则表达式进行解析,获取具体的数据字段。将获取的具体数据库异步存入数据库,以便分析。设计缓存和异常处理机制:使用缓存避免重复爬取,处理各种异常情况如网页解析错误等。使用线程、协程提高爬取效率。
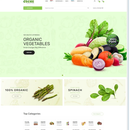
国有企业电商网络平台,使用Django、HTML、Js、CSS、Jquery、Mysql、信息加密解密技术、信息分块传输技术等构建的国企电商平台。
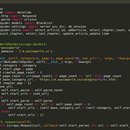
基于二手车交易数据的二手车估值平台项目 构建日均爬取20万条以上数据的网络爬虫,从二手车交易平台获取车辆的报价、售价、使用及保养情况等数据,通过机器学习算法对二手车进行估值。主要使用工具:Scrapy、Redis、Django、Mysql。






