

普通话
粤语
0
1
2
3
4
5
0
1
2
3
4
5

 ********
******** ********
********大家好,我是一名Python工程师,专注于智能方向的开发。我很高兴有机会向大家介绍一下我的背景和经验。 我在编程领域有着丰富的经验,特别是在Python开发方面。我熟悉Python语言和相关的开发工具,能够利用Python构建高效、可靠的应用程序。我对数据分析、机器学习和人工智能等领域有着浓厚的兴趣,并在这些领域进行深入研究和开发。 在我的职业生涯中,我有幸发表了7篇论文、4篇软件著作权和两个发明专利。这些作品涵盖了智能方向的技术和创新,并得到了同行的认可。我喜欢将学术研究与实际应用相结合,致力于开发能够解决实际问题并提升用户体验的智能系统。除了学术研究,我也具备团队合作和沟通能力。我乐于与其他开发人员、数据科学家和产品团队合作,共同推动项目的成功。我注重代码的质量和可维护性,喜欢探索新的技术和工具,以不断提升自己的技能和知识。 作为一名Python工程师,我热衷于解决复杂的问题,并希望能够为推动智能技术的发展做出贡献。我对未来的发展充满期待,期望能够在智能领域取得更多的成就。
2024-06-06 -2024-07-31金溪土鸡小程序开发
该公司专注于土鸡产品的营销领域,采取线上线下深度融合的创新运营模式。在此背景下,我承担了关键角色,主要负责运营仓库的数字化升级工作,具体涉及开发一款高效的小程序,以构建全面且易于管理的仓库后端管理系统。目前,这款精心打造的小程序已成功上线并投入使用,极大地提升了仓库运营的效率与透明度。
2021-09-01 - 广东东软学院电子信息工程本科已认证

新闻文本分类任务在信息检索、舆情检测与分析、信息智能推送等领域发挥着重要的作用。为了解决传统卷积神经网络在新闻文本分类中效果不佳的问题,本文提出了一种改进的BERT-UNet文本分类模型,来增强捕捉长距离文本特征和可视化效果。首先该模型使用BERT预训练文本词向量,然后将其嵌入映射到UNet模型中,提取上下文的关键特征,同时通过Softmax函数实现文本分类,最后利用前端技术对新闻舆情信息文本分类结果进行可视化监控展示。为验证模型在文本分类任务上的优越性,本文进在THUCNews数据集上进行了对比实验,实验结果显示,相较于传统模的TextCNN模型和独立使用BERT的方法,BERT-UNet模型在宏平均F1值上分别提高了3.11%和0.29%。这表明改进的BERT-UNet模型在捕捉文本特征关系方面更有效,在提升分类性能,改善传统新闻文本分类方法及可视化监控提供了新思路。
DataFlowGen是一个集成多种数据处理功能的使用工具,这个工具允许你执行不同的功能,包括重命名文件、去除重复数据、将XML格式的标注文件转换为TXT格式,以及创建数据集。 希望这个脚本可以帮助您处理大模型数据,提高你的工作效率,祝愿您在AI领域取得更大的成就!
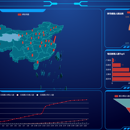
新型冠状病毒感染疫情数据高效率利用一直是值得研究的问题,到目前为止,还没有一个完美的可视化工具能满 足医疗学科对疫情的要求。文章基于 Django 网络框架,借助 ECharts 完成疫情数据可视化处理和界面的交互功能,通过爬虫获 取疫情数据并建立数据库,完成网页端可视化界面多元化疫情数据展示的构建,可视化内容涵盖各省市的确诊数、死亡数等,疫 情数据可视化平台的搭建为广大人民群众和医疗从事人员了解疫情提供技术支持。






