

0
1
2
3
4
5
0
1
2
3
4
5

 ********
******** ********
********数据分析师在职;熟悉 python 数据分析,了解 python 数据分析的一些常用算法(分类、回归分析、聚类、关联规则),了解一些常用的可视化分析方法,seaborn,tableau等;熟悉爬虫,熟悉常用的爬虫方法( requests Selenium Scrapy )等;熟悉Linux操作系统;有扎实的数据结构基础。
2022-09-01 -至今宜通衡睿科技有限公司数据分析师
持续审计,参与中国移动广东公司内审部持续审计项目小组,负责持续审计等工作,具体为参与审计项目,为数据审计提供意见,协助出具持续审计报告,协助进行集团系统数据治理,核对审计报告。 数据分析,对审计相关数据进行分析,利用 sql、python 等对数据进行筛选、核查,利用 SQL、EXCEL 等对数据进行处理。兼任中国移动省公司内审部助理,负责提单取数、核对整理数据、账号安全,协助进行数据安全相关工作。
2018-09-01 - 2022-07-01广州商学院数据科学与大数据技术本科
数据科学与大数据技术专业,在校主修课程有数据库原理与应用、数据采集技术、大数据分析与应用、数据可视化技术、web应用开发、人工智能应用技术等
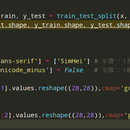
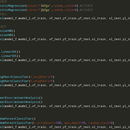
利用深度学习中的卷积神经网络以及图像处理的技术,将从网上获取到字母图片数据集进行图像识别,包括对原图像的进行预处理,用tensorflow对进行图像识别时,还将采用卷积神经网络来构建模型,本次实验将分为未采用卷积神经网络进行图像识别,采用卷积神经网络以及采用卷积神经网络加数据增强这几个步骤,依次对比各种训练方法对图像识别的准确率。
采用DataCo Global 公司使用的供应链数据集,对数据集客户细分分析,目的是使公司更好地了解其客户,并针对他们提高客户响应能力和公司收入。由于分析数据有很多选择,很难决定使用哪种方法和机器学习模型,因为模型的性能随数据中可用的参数变化而变化。所以同时比较9种流行的机器学习分类器,以找出哪种机器学习模式的效能更佳。由于所使用的数据集与供应链相关,因此对重要参数进行检测,并使用该数据集训练机器学习模型,以检测欺诈交易、订单延迟交货。本项目使用的机器学习分类器有Logistic回归、线性判别分析、高斯朴素贝叶斯、支持向量机、k-近邻、随机森林分类、extra树分类、极端梯度增强、,决策树分类用于欺诈检测,并根据准确率、召回分数和F1分数预测延迟交货。 具体实现步骤是先对数据集进行一个探索性分析,查看数据集的变量,去更加深入探究各个变量间的联系,并对数据集的部分信息进行可视化展示,构建分类模型

爬取步骤: 1、首先cmd启动scrapy,生成爬取去哪儿网的scrapy文件夹,包含spider、pipline、setting等文件,指定域名。 2、编写主要爬虫文件spider,首先爬取主页上的字段信息以及详细页的网址,然后获取到详细页的网址后,通过回调函数进入到详细页爬取。主页爬取采用re。 3、在进入到详细页之前,大部分详细页网站会被重定向到一个中间页面,中间页面里有详细页的网址,通过re获取到所要的 详细页网址,继续通过回调函数进入详细页 4、进入到详细页后,通过response返回的内容获取到要爬取的 字段信息,接着发现部分信息需要更进一步到动态加载内容中获取,继续用回调函数进入到动态加载网页中 5、进入到动态加载网页需要携带参数、携带参数进入后通过json转换获取到要爬取的评论数等信息 6、在setting里设置请求头和代理ip池,并且到midware中间件设置爬取时更换ip 7、设置item和pipline将数据保存到csv文件中去




