

0
1
2
3
4
5
0
1
2
3
4
5
 ********
******** ********
********我是程序员客栈的debugger_1013,一名深度学习医学图像处理方向的在读研究生;
我现在就读于北方工业大学(2025.6硕士毕业),担任过北京博识创智科技发展有限公司的技术支持工程师;
负责过公司的无线信号基因库的建设,对各种无线通信制式进行行业调研,也曾为无线信号调制识别的项目提供技术支持;
熟练使用python、pytorch框架、常用的深度学习网络和常见的机器学习算法、AI方向应用、matlab语言和C语言;
如果我能帮上您的忙,请点击"立即预约"或“发布需求!
2022-04-18 -2023-07-29北京博识创智科技发展有限公司技术支持
1. 无线电监测领域行业调研:其他同行无线电一体化招投标项目调研 2. 各类无线通信无线制式调研:补充无线信号基因库信息 3. 用MATLAB生成常见雷达信号及其时频图 4. 将北京市几个站点采集到的信号的频谱和IQ数据进行过滤,筛取主要频段的数据 5. 用VGG网络对采集到的IQ信号或时频图进行训练,提高调制识别的精度
2022-08-23 - 北方工业大学信息与通信工程硕士
2017-09-06 - 2021-06-25北方工业大学通信工程本科

1. 该项目功能包括二类/多类loss设计、模型融合、阈值dice指标设计、数据集设计、模型训练和测试。该项目的目的是识别并分割五类人体器官的功能组织单位,提高模型跨越多个器官的泛化性和鲁棒性。数据来源于kaggle平台的公开数据集:HuBMAP + HPA - Hacking the Human Body,输入图像为.tiff格式,图像中的标注信息包含RLE编码过的mask,使用者可以使用该项目分割出人体器官对应的mask,可将mask编码为RLE格式 2. 将.csv文件中的RLE信息转换成.png格式的mask。训练集图片有351张,数据量少,且图片的分辨率很大(3000×3000),因此需要对图像进行切patch操作。训练过程中使用多折交叉验证的训练策略,提高数据的利用率。设计动态门限,找到对应dice值最高的门限值。通过消融实验验证efficientNet、FPN、UneXt50、和ASPP模块的作用(是否会影响指标),最终融合这些模块。在测试阶段使用TTA,提高模型的泛化能力。设计二类/多类loss,二类loss用于预测每个像素是否属于mask,多类loss用于得到该图像属于哪类器官组织的概率。验证集当阈值取0.55时,dice值最高为0.83,测试集最佳dice为0.65
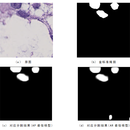
1. 该项目可分为数据预处理、数据集设计和划分、网络模型、模型训练、模型测试、界面设计几个模块。该项目的目的是为了从人体多种组织细胞的病理图像中,分割出癌细胞核,以辅助医务人员和科研人员对于癌细胞的研究和癌症的诊断。输入可以选择测试集中的一张细胞病理图像,输出为模型预测出的癌细胞核的mask。使用者可以根据自己的实际需要调整界面控件(按钮、输入输出图像显示、文本框等)的摆放位置、控件数量,调整预测接口以输出定制化的预测结果(如输出图像中癌细胞核的mask和细胞原图的所属类别)。该项目的输入数据来源于kaggle平台提供的公开数据集:Cancer Instance Segmentation and Classification,使用者可以根据数据集之间的差异修改项目中的数据集模块。根据指标需要替换和修改网络模型以进一步提高指标。通过修改mask的通道,该项目还可以实现其他细胞核的分割:炎性细胞、结缔/软组织细胞、死细胞和上皮细胞。 2. 由于images.npy文件很大,直接读取和进行数据处理,读取速度慢、资源开销大,而且.npy文件不便于可视化,因此需要进行数据预处理,将images.npy和masks.npy转为.png格式的可视化图像,而且该数据集中有部分未标注数据,由于选用全监督方法进行训练和测试,需要对这部分数据进行滤除(避免影响网络训练)。网络模型采用Mask RCNN,可用于实例分割。界面部分是自主设计的,可以实现从测试集中任意选择一张图片,然后输出预测出的mask图像的功能。验证集最佳AP可达到81%,最佳AR可达到64%;测试集最佳AP可达到70%,最佳AR可达到54%。

1. 项目功能分为:数据预处理、坐标建模、轨迹分析、坐标聚类、生成聚类中心图和输出时间及位置信息。该项目的输入包括车辆ID、经纬度、方向、速度、状态(0:空载、1:有载客)、数据发送时间(年月日时分秒)、数据接收时间、行政区号和具体位置等信息,数据格式为.txt文件。该项目的目的是根据每辆车的轨迹信息,时间先后,及状态(有无载客)来确定上下车集中的位置和时间,本质上是实现坐标点的聚类。使用者可以修改输入数据(使用前需要将.txt格式转为.csv格式),替换和修改聚类算法,找到更加精确的聚类中心,提高预测精度。本项目中确定聚类中心的距离指标是欧氏距离,使用者可以根据实际需要修改为其他距离指标(如:曼哈顿距离) 2. 本项目的难点在于数据筛选、坐标建模以及聚类中心的确定。将txt文件转为csv文件便于进行后续的数据处理,该数据集包含20万条车辆信息,包括:车辆ID、经纬度、方向、速度、状态(0:空载、1:有载客)、数据发送时间(年月日时分秒)、数据接收时间、车辆类型(全为0:出租车)、行政区 号和具体位置,其中与项目相关的数据包括:车辆ID、经纬度(上下车点)、状态、数据发送时间(将该时间视为该车当时所处的时间点)、行政区号和具体位置。将经纬度转为位置坐标,根据车辆ID分组,然后按照时间先后进行排序,查看每辆车的运行轨迹以及载客状态的变化,根据肘部原则确定聚类中心的个数,使用K-means算法确定聚类中心的位置,生成聚类中心图,然后找到距离聚类中心最近的点,将该点的时间和位置信息(行政区号和具体位置)打印为一个文本





