

0
1
2
3
4
5
0
1
2
3
4
5
 ********
******** ********
********1. 擅长使用多种编程语言和开发工具进行软件开发;
2. 丰富的项目经验,快速理解业务需求并提供高质量的解决方案;
3. 善于沟通、理解和表达,具备优秀的团队协作能力;
4. 拥有完整的项目开发迭代经验及前后端开发经验。
2023-06-15 -至今西安图宾科技有限公司视觉算法开发
1. 负责算法研发:设计和实现图像处理算法和计算机视觉算法。根据问题需求进行算法研究和创新,提高算法的准确性和效率。 2. 模型训练和优化:使用深度学习框架(TensorFlow、PyTorch)构建图像识别、目标检测等模型,并进行训练和优化。调节和调优模型的超参数,优化损失函数,提高模型的性能和泛化能力。 3. 算法集成与优化:将开发的算法集成到软件系统或应用中,设计和实现相应的接口和功能。优化算法的执行效率,考虑算法在不同硬件平台上的部署和加速。 4. 技术文档和报告:记录算法设计和实现的细节,撰写技术文档和报告,以便于团队成员的交流和合作,并为日后复用和扩展提供参考。 5. 跟踪新技术:关注图像算法和计算机视觉领域的最新研究和技术趋势,学习和掌握新的算法和工具,不断提升自己的专业水平。
2021-07-01 -2022-09-01中国航空第631所图像算法工程师
负责智慧座舱系统的研发,我负责的功能模块包含:眼动追踪,手势识别,夜视增强,图像去噪和超分辨率,以及使用QT搭建跨平台框架。
2014-08-01 -2020-07-01北京品西互动科技有限公司Python爬虫及后端开发
1. 网络爬虫开发:设计和实现高效的网络爬虫程序,从指定的自媒体平台或者网站上获取文章、视频、图片等相关内容。了解并遵守相关网站的爬虫规则和协议,保证爬虫程序的合法性和稳定性。 2. 数据抓取和解析:通过编写爬虫程序,从自媒体平台上抓取所需的文章、评论、转发数、点赞数、阅读数等数据,并进行数据解析和提取。根据自媒体平台的页面结构和数据格式,编写相应的解析规则和算法。 3. 数据清洗和处理:对抓取到的原始数据进行清洗和处理,包括去除重复数据、修正错误数据、统一数据格式等。根据业务需求,对数据进行筛选、过滤或者预处理,以便后续的分析和应用。 4. 数据存储和管理:将清洗和处理后的数据存储到数据库中,建立合适的数据模型和表结构。优化数据库的查询性能和存储方案,确保数据的安全性和一致性。 5. 数据分析和挖掘:对爬取到的自媒体数据进行分析、挖掘和统计,提取有价值的信息和洞察,如热门话题、关键词分布、用户行为等。使用相应的数据分析工具和算法,发现潜在的趋势和模式。 6. 后端接口开发:使用Python语言开发后端接口,提供给前端和其他系统进行数据交互和业务逻辑处理,并编写API接口文档 。
2020-09-01 - 2023-06-21西安石油大学计算机技术硕士
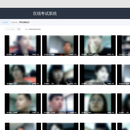
项目描述: 线上开考缺少有力的监控手段,考试环境由考生自己控制,可操作空间极大,为了保障考试的公平公正,规避作弊及违规等现象发生,需要专业的智能监考平台针对线上考试提供支撑。该项目使用PyTorch + Django+ MySQL + PyQt5进行开发,使用Python 构建RESTful风格的API,实现前后端分离,前端使用QT等框架。智慧监考系统的主要功能功能包括:身份认证、考试时间及规则配置、考生监控视频录制、监考视频统计及下载。 项目难点: 1. 实时监控视频处理:使用WebSocket和OpenCV处理实时监控视频,实现高效的视频传输和处理 2. 身份认证技术的集成:使用Django-Authentication实现用户身份认证和权限管理。 3. 考试规则的灵活配置:设计灵活的考试规则配置,满足不同考试场景的需求。 4. 数据安全和隐私保护:确保数据安全,保护用户隐私。 我的职责: 负责数据库设计实现身份认证、考试时间及规则配置、考生监控视频录制以及监考视频统计及下载等核心功能的实现,以及技术难点突破,带领小组按时推进项目。优化实时监控视频处理技术,确保系统性能和稳定性。
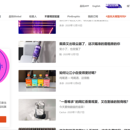
项目描述: 品玩是一个主要关注科技资讯和新闻的自媒体网站,分为中文和英文两个版本,主要报道科技新闻、创业动态、互联网行业动态、产品评测等内容。品玩后台管理系统采用Django + Redis + MySQL + Html的软件架构,是一个集用户管理、内容管理、分类与标签管理、评论管理、广告管理、数据统计与分析、消息通知管理、短视频评测管理、线下活动管理、数码产品直播管理和系统设置与维护的大型管理系统 。 项目难点: 1. 数据库设计:自媒体网站需要存储大量的文章、评论、用户等数据,因此需要进行合理的数据库设计,包括表结构设计、索引设计等。 2. 接口设计和测试:RESTful API需要设计合理的接口,包括URL、HTTP方法、请求参数、响应格式等,需要考虑接口的可扩展性、易用性、安全性等因素。接口开发完成后,需要对API进行全面的测试,包括单元测试、集成测试、性能测试等,以确保API的稳定性和可靠性。 3. 高并发处理:网站在直播时会面临大量用户同时访问的情况,需要处理高并发请求,需要合理使用Java多线程、线程池技术和Redius缓存策略。 4. 搜索引擎优化:对于文章搜索功能,使用搜索引擎库(Elasticsearch)进行搜索引擎优化。通过优化搜索算法、使用缓存、压缩数据、使用索引等手段提高搜索效率和相应速度。 5. 内容推荐算法:为用户提供个性化的内容推荐,需要设计和实现合适的推荐算法。系统采用基于用户的协同过滤算法实现个性化内容推荐。 6. 系统可扩展性:使用模块化设计和框架实现系统的可扩展性。可以将不同功能模块划分为独立的服务,使用微服务架构,通过消息队列或 RPC 实现模块之间的通信,以支持更多功能和更大的用户量。 7. 数据安全和隐私保护:使用 Django 的认证和授权机制进行数据安全和隐私保护。确保用户数据受到合理的保护,并且防止恶意攻击。 我的职责: 1. 需求分析:与产品经理和UI设计师合作,分析需求,确定系统功能和技术实现方案。 2. 系统设计:设计系统架构,包括数据库设计、API设计、模块划分等。 3. 编码实现:根据需求和设计文档,使用Java语言编写高质量的代码,实现后台管理系统和RESTful API。 4. 单元测试:编写单元测试代码,保证代码质量和系统稳定性。 5. 系统集成:与前端开发人员合作,完成前后端集成,确保系统功能正常。 6. 系统优化:对系统进行性能优化和调优,提高系统响应速度和并发处理能力。 7. 系统维护:对系统进行维护和升级,修复漏洞和BUG,保证系统的稳定性和安全性 8. 技术研究:研究新技术和新框架,提高自身技术水平,为系统的优化和升级提供技术支持。
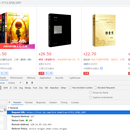
项目简介: 该项目旨在通过爬虫技术获取京东图书类商品的相关数据。通过对京东网站的爬取,获取到图书的名称、作者、出版社、价格、评论等信息。 项目分为以下模块: 网页解析模块:通过使用 Selenium 进行 HTTP 请求解析网页结构,提取所需的信息。 数据存储模块:将爬取到的数据存储到数据库或文件中,以便后续处理和分析。 反爬虫处理模块:由于京东网站可能会采取反爬虫措施,需要编写相应的代码来应对,如设置合适的请求头信息、使用代理IP等。 并发控制模块:为了提高爬取效率,可以使用多线程或异步编程技术实现并发控制,同时发送多个请求并处理响应。 我负责的内容包括: 项目规划和设计:确定项目的需求和目标,分析数据结构和流程,制定爬虫策略和算法。 网页解析模块的实现:编写网页解析代码,根据需求提取出图书的相关信息。 数据存储模块的实现:选择合适的数据库或文件格式,编写代码将爬取到的数据进行存储。 反爬虫处理模块的实现:分析反爬虫机制,编写相应的代码来绕过反爬虫措施。 并发控制模块的实现:根据实际需求选择合适的并发技术,编写代码实现并发控制。 项目的难点及解决方法: 反爬虫机制:京东网站可能采取IP封禁、验证码等手段进行反爬虫,可以使用代理IP池、自动识别验证码等技术来应对。 动态网页加载:部分图书信息可能通过Ajax或其他动态加载方式呈现,可以使用Selenium等工具模拟浏览器行为,获取完整的页面数据。 大规模数据处理:京东图书数据庞大,需要考虑如何高效地处理大量数据,可以使用分布式爬虫、多线程或异步编程等技术来提高效率。 数据一致性和准确性:由于网页结构可能变化,需要定期检查和更新解析代码,保证爬取的数据准确且一致。 京东网站解析的复杂性:使用传统的解析库难以正确地提取所需的信息。使用Selenium以选择元素并提取数据。 总体来说,该项目涉及到网页解析、数据存储、反爬虫处理和并发控制等方面,需要综合运用多种技术来完成任务。





