

0
1
2
3
4
5
0
1
2
3
4
5

 ********
******** ********
********我是程序员客栈的besttttttttttt,一名大数据开发; 我毕业于徐州工程学院,分别担任过苏州鲜橙科技有限公司和无锡朗帆信息技术有限公司的数据开发,负责的项目,分别是小程序用户行为日志分析系统、CBD大数据分析平台,和国联人寿"方舟-大数据平台"精算系统和用户画像系统。 如果我能帮上您的忙,请点击“立即预约”或“发布需求”!
2021-07-01 -2023-02-10无锡朗帆信息技术有限公司数据开发
无锡朗帆信息技术有限公司是一家以从事专业技术服务业为主的企业; 我的职责:1.参与需求文档分析阶段,根据产品提供的去求划分主题,辅助构建需求文档 2.根据业务关联关系分析指标,建立数仓分层模型 3.负责实现将业务数据划分全量及增量,构建全量及增量同步脚本实现ODS层数据同步 4.负责保费参数因子计算,以及后续的保费计算 5.负责项目中业务指标统计分析,现金价值指标计算工作 6.开发数据同步、数据主题的Shell脚本,基于DS实现任务流调度的设计及测试 7.负责解决临时的一些问题,例如数据同步不一致、数据倾斜等问题
2019-04-01 -2021-06-12苏州鲜橙科技有限公司数据开发
公司是一个社区O2O团购服务平台,以社区为单位,建立社区营业点、线下完成交付,平台提供货源、物流仓储及售后支持,主要提供初级食用农产品,食品,日用品,鲜花园艺,工艺品,美妆产品等服务。 我的职责主要是1.参与项目的立项会议,参与编写项目的需求文档 2.制定离线数仓开发规范,设计表命名,字段命名,字段类型等规范 3.负责将存储在MySQL数据库中的业务系统数据导入HDFS上 4.负责实现每个分层的数据抽取、转换、加载 5.负责编写Shell实现Sqoop脚本批量导入数据,并实现Oozie任务流调度 6.负责使用SparkSQL进行数据应用层指标进行分析
2015-09-01 - 2019-07-01徐州工程学院信息管理与信息系统本科
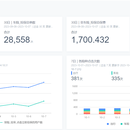
项目架构:CM+ZooKeeper+HDFS+Yarn+Hive+Spark+Sqoop+DS+Springboot 项目描述:本项目是一个国联人寿保险的重构项目,由于整个精算系统重构之前是基于Oracle 计算的,计算过程过于复杂,而且需要专业的Oracle DBA参与,项目维护非常麻烦。项目负责人选择更换使用 Spark SQL 进行迭代计算操作完成整个精算计算操作。该项目对计算流程进行了拆解,简化难度,提升维护性,以及提升效率,通过维度建模及数仓分层来简化SQL的难度,提升维护性,减低成本。为此通过 CDH 平台整合多险种业务源数据,利用大数据海量数仓的分析能力,精细化处理保险业务,达到精算保险的目的。 职责描述:1.参与需求文档分析阶段,根据产品提供的去求划分主题,辅助构建需求文档 2.根据业务关联关系分析指标,建立数仓分层模型 3.负责实现将业务数据划分全量及增量,构建全量及增量同步脚本实现ODS层数据同步 4.负责保费参数因子计算,以及后续的保费计算 5.负责项目中业务指标统计分析,现金价值指标计算工作 6.开发数据同步、数据主题的Shell脚本,基于DS实现任务流调度的设计及测试 7.负责解决临时的一些问题,例如数据同步不一致、数据倾斜等问题
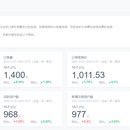
项目架构:CM+ZooKeeper+HDFS+Yarn+Hive+Spark+Sqoop+Hue+Oozie+FinBI 项目描述:本项目是基于同程生活研发的大数据分析平台,公司业务覆盖华东、华中及华南等地区,日服务家庭超过几百万,月交易额数千万元人民币。为了避免疫情大爆发给公司带来巨大影响,突破运营瓶颈,增加公司营业额,提高用户量和订单量。因此对大量的业务数据进行综合分析,依据数据分析报表展示的结果,能使公司更加清晰地把握业务运营状况,通过更少的投入获取更大的收入比。 职责描述:1.参与项目的立项会议,参与编写项目的需求文档 2.制定离线数仓开发规范,设计表命名,字段命名,字段类型等规范 3.负责将存储在MySQL数据库中的业务系统数据导入HDFS上 4.负责实现每个分层的数据抽取、转换、加载 5.负责编写Shell实现Sqoop脚本批量导入数据,并实现Oozie任务流调度 6.负责使用SparkSQL进行数据应用层指标进行分析
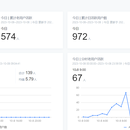
项目架构:MySQL+Sqoop+Flume+Zookeeper+Hive+Spark+Elasticsearch 6.8+Oozie 项目描述:本项目是基于国联人寿数仓平台构建的用户画像系统,为了实现平台利益的最大化,精准营销,提高用户投保率,项目主要依据用户信息、用户行为数据以及用户的保单信息等多方面的数据源提炼影响用户投保核心特征,使用Spark对用户打上标签,构建用户画像标签体系,打完标签后将数据存储在ES中,构建二级索引,实现对用户的精准营销和精细化运营。 职责描述:1.负责将数据导入至Hive,并进行ETL过滤脏数据 2.负责开发SparkSQL程序,完成规则类型标签,且通过自定义UDF函数和模板设计模式编写工具类 3.负责使用业务数据中相关字段进行统计分析,结合标签规则开发统计类型标签 4.参与基于KMeans算法,建立特征工程,训练出最佳模型,对该模型进行评估,从而完成RFM和RFE模型的开发,对用户进行预估分析,再配合MySQL中的属性标签给用户打上标签,存储到ES中 5.简化SparkSQL程序中读写画像标签数据操作




