

0
1
2
3
4
5

 ********
******** ********
********我是程序员客栈的浮生,一名计算机技术方向人员 目前就读西北师范大学,硕士在读 负责过THUCNews文本分类,天池糖尿病中文文本分类,文本相似度计算的开发; 熟练使用python语言,熟悉pytorch框架以及深度学习各种模型 如果我能帮上您的忙,请点击“立即预约”或“发布需求”!
2024-01-01 -2024-01-19知行合越开发人员
并没有实质工作,目前还未参加工作,但是有较多的python项目经验,熟悉深度学习框架。
2022-09-01 - 2024-01-19西北师范大学计算机技术硕士
该任务主要使用哈工大LCQMC数据集。LCQMC数据集是一个文本匹配数据集,它是基于人机对话任务的一项基本任务,通常被认为是语义匹配任务,有时是释义识别任务。本节的目标是计算两个文本的相似度,并得出是否相似的结果,相当于一个二分类问题。语料库包含260,068个带有人工注释的问题对,我们将其分为三部分,即包含238,766个问题对的训练集、包含8,802个问题对的验证集和包含 12,500个问题对的测试集。

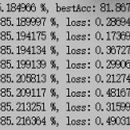
使用TextCNN对清华大学的新闻预料进行分类。由于硬件限制,只能对一个小型的数据集进行分类,首先对数据进行拆分,通过取出每个类别中的5000条数据构建一个小型的语料库,取其中的65%作为训练集,剩下的作为测试集,并将这65%的训练数据每个分类中的文本全部存放到一个文本中,测试数据也是如此。训练结束后在测试集上的准确率可达85%。




