精通Python语言,熟练使用常用模块,使用过Django/Tornado等web框架;
具备良好的编码习惯;熟悉常用算法和数据结构,熟悉基础的网络知识,精通网络编程和多线程;扎实的统计编程能力,Python 水平高级、熟悉 SQL;
熟悉掌握常用爬虫框架,Scrapy、Selenium、Puppeteer和Splash等。熟悉爬虫原理,熟悉Scrapy、pyspider等主流爬虫框架框架,能够解決封账号、封IP、验证码、网页限制爬取等等问题,且有实际经验;
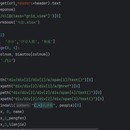
查看豆瓣电影网指定城市或在指定类型的数据排行榜,通过xpath提取或beautifulsoup方式进行数据解析,最后通过os模块进行数据保存
 0
02024-03-22 11:10
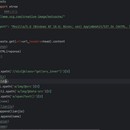
通过request请求请求网页,得到响应数据后,利用xpath提取方式对数据进行解析提取,使用os模块对数据进行保存在指定路径。
0 2024-03-22 11:07
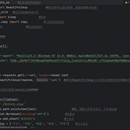
独立爬取指定公开数据,精通Python语言,熟练使用常用模块。具备良好的编码习惯,熟练掌握常用爬虫框架Scrapy、selenium。熟悉爬虫原理,熟悉基础的网络知识,精通网络编程和多线程。且有实际经验
0 2024-03-22 11:00



 ********
******** ********
********





