



点击空白处退出提示
团队技术信息
团队规模:6-15人
团队组成:后端Java2人 ,前端前端1人 ,设计师UI设计师1人 ,测试测试1人 ,产品经理产品经理1人 ,高端技术职位项目经理1人 ,高端技术职位架构师1人 ,运维运维1人
技术栈:JAVA,vue,python,unity
公司信息
成立时间:暂无企业状态:正常
注册资金:暂无实缴资本:暂无
案例

AR导航平台是一种基于增强现实技术的创新地图导航方式,通过实时捕捉的真实画面与地图导航引导信息的结合,为用户提供直观且便捷的导航体验。它能够将虚拟的导航指引模型叠加到真实场景上,让用户更加清晰地了解自己当前的位置以及前往目的地的路径。 技术栈方面,AR导航平台主要依赖于以下关键技术: 摄像头实时捕捉技术:AR导航平台首先利用设备的摄像头实时捕捉周围环境画面,作为导航的基础场景。 视觉AI识别技术:结合深度学习等算法,平台能够识别车辆、道路、行人等场景目标,从而为用户提供更为准确的导航指引。 地图导航技术:利用传统的地图导航数据,包括道路、建筑、兴趣点等信息,为用户提供详细的导航路线。 增强现实技术:通过计算机图形技术,生成虚拟的3D导航指引模型,并将这些模型与真实场景进行融合,实现增强现实的导航效果。
2024-04-10 16:52
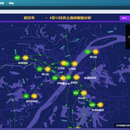
智慧环卫平台是一个专门为环卫监管部门和环卫企业量身打造的综合管理平台,旨在提升环卫工作的效率和质量。它集成了多种智能技术和功能,通过人、车、物、事、财等多个维度为环卫工作提供全方位的支持和管理。 该平台的技术栈主要包含了以下模块: 道路清洁控制:前端安装环卫车辆管理设备,可以综合监控机械化清洁操作、道路清洗操作车辆的实时位置、操作频率、操作轨迹、覆盖次数、操作面积、操作状态、操作规范、清洁里程、违规、清洁质量等信息。 环卫车辆管理:展示当前全部车辆数据信息,及维修保养、保险缴纳、历史轨迹等数据。此外,可以设定指定车辆电子围栏,防止车辆乱跑乱停等违规现象,有效监管各车辆。 电动保洁车管理:类似于环卫车辆管理,但专门针对电动保洁车辆。可以展示当前全部电动保洁车辆数据信息,包括交接记录、电池更换记录、维修记录、历史轨迹等,同样设有电子围栏功能,以防止违规行为。 设施管理:主要负责环卫设施的管理,包括设施信息管理、设施维护保养、故障报修以及设施使用情况监控等功能。管理者可以实时监测环卫设备的工作状态和运行情况,及时发现故障并进行维修,确保设备的正常运转,提高设施使用效率,降低设施故障率。 事件管理:负责对环卫工作中的事件进行管理,包括问题上报、事件处理、处理进度跟踪以及事件统计分析等功能。根据实时的数据和需求,管理者可以快速响应和处理环卫工作中的问题,合理安排环卫工人的工作路线和时间,最大程度地提高工作效率,提升服务质量。 数据中控台:大数据可视化展示平台各实时数据,包含当日考勤、工作预警、车辆状态、车辆越界报警及巡查照片等,方便用户直观检查各项主要数据。 在技术实现上,智慧环卫平台采用了大数据可视化分析功能,通过自动抽取环卫系统中的各种历史数据,合纵连横,分析挖掘,直观可视化展示,为管理者决策提供数据支持。同时,该平台的数据分析系统可多维度挖掘营业数据价值,有助于企业管理和决策的科学化。 此外,该平台也考虑到了与市民的互动,培养居民的环卫主动参与意识,促进环卫工作正向良性循环,环境的改善将提升政府和居民对环卫服务的满意度。
2024-04-10 16:46
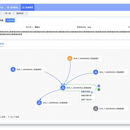
大数据中台是一个集中化、标准化的数据服务平台,旨在为企业或组织提供高效、稳定的数据处理、分析和应用服务。它整合了企业内外的各类数据资源,通过数据抽取、清洗、转换、存储等操作,将原始数据转化为有价值的资产,为企业的决策提供数据支持。 大数据中台的技术栈涵盖了多个关键组件和工具,形成了一个完整的数据处理和分析生态系统。以下是一些主要的技术栈元素: 数据采集与传输层: Flume:一个分布式、可靠、高可用的数据采集、聚合和传输系统,常用于日志采集系统,支持定制各类数据发送方,用于收集数据,通过自定义拦截器对数据进行简单的预处理并传输到各种数据接收方。 Sqoop:主要用于Hadoop(如HDFS、Hive、HBase)和RDBMS(如MySQL、Oracle)之间的数据导入导出。 Kafka:分布式消息系统,主要应用在数据缓冲、异步通信、汇集数据、系统接偶等方面。 Pulsar:pub-sub模式的分布式消息平台,拥有灵活的消息模型和直观的客户端API。 数据存储与管理层: HDFS(Hadoop Distributed File System):用于存储海量数据,具有高容错性、高吞吐量的特点。 HBase:一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,用于存储非结构化和半结构化数据。 Hive:一个基于Hadoop的数据仓库工具,用于处理和分析结构化数据。 数据计算与处理层: Spark:一个快速、通用的大规模数据处理引擎,支持批处理、流处理、图计算和机器学习等多种计算模式。 Flink:一个开源的流处理框架,支持高吞吐、低延迟的数据处理。 数据服务与应用层: 数据API服务:提供数据查询、分析和可视化等功能的API接口,供外部应用调用。 数据可视化工具:如Tableau、PowerBI等,用于将数据以图形化的方式展示,便于理解和分析。
2024-04-10 16:53


