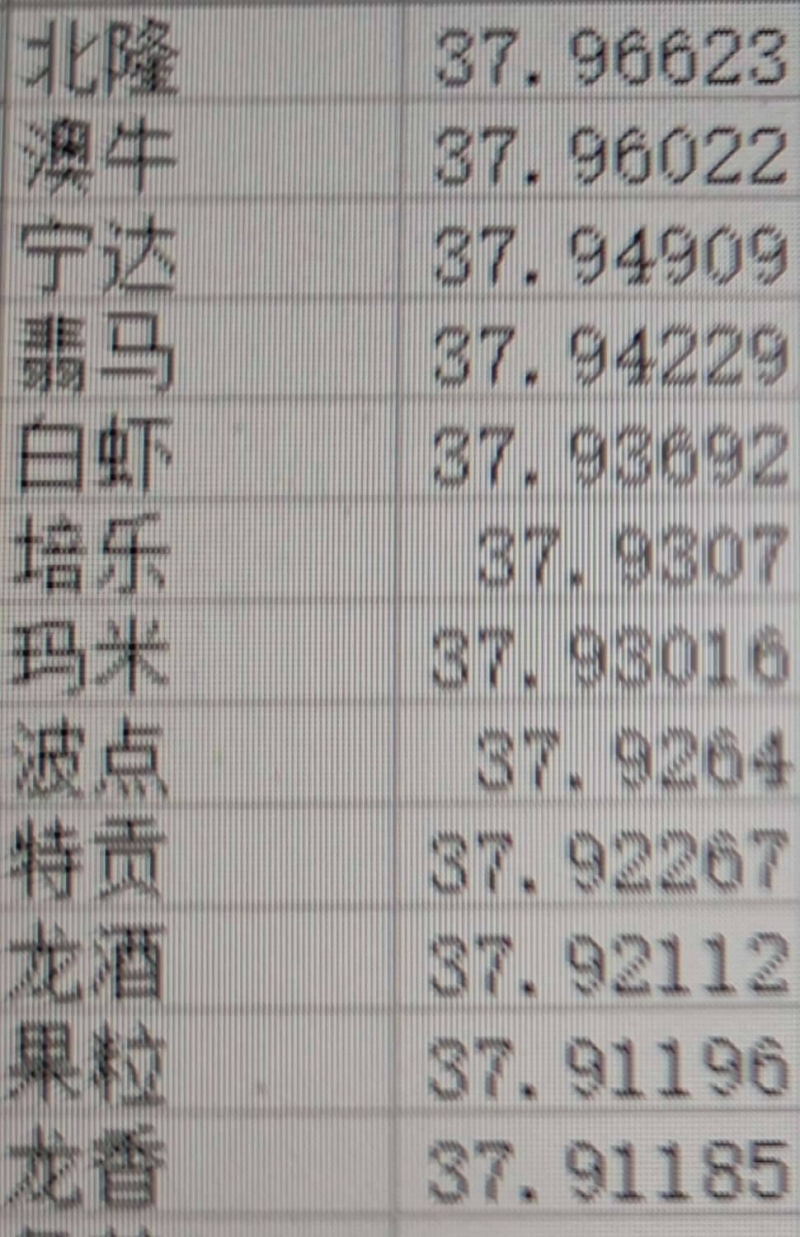
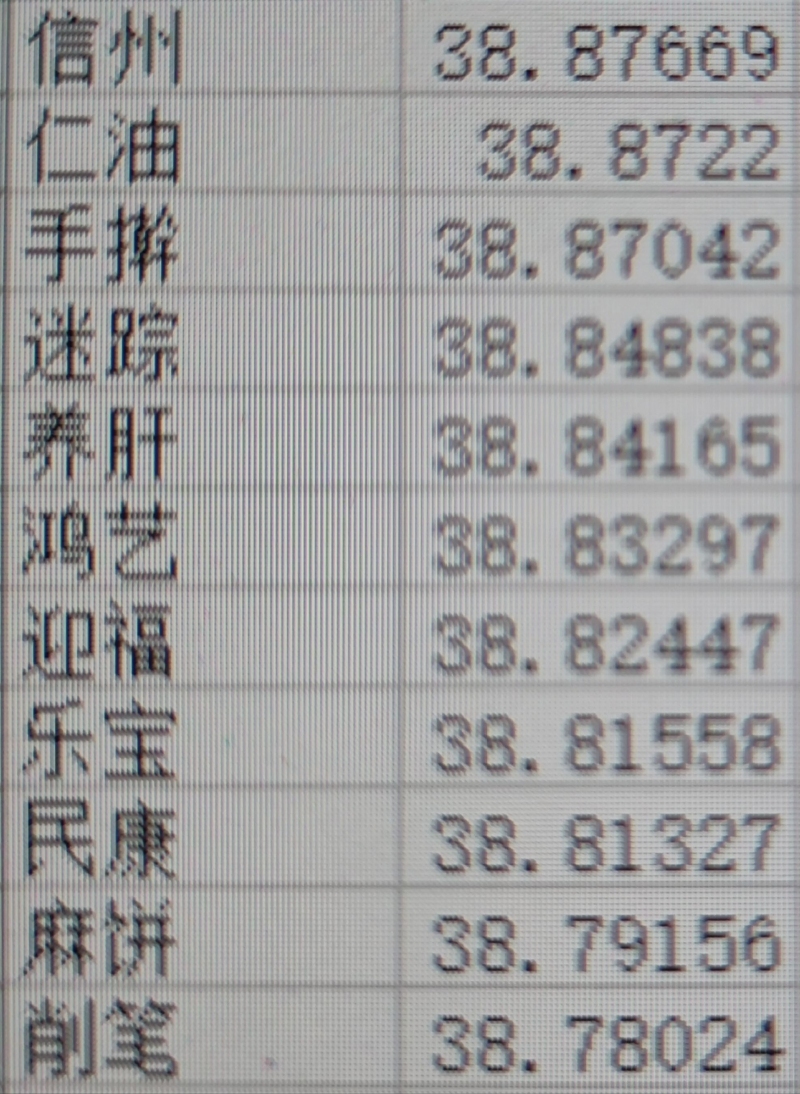
通过bert推理出每个token的embedding,再计算语料中相邻token之间的相似度,高于阈值就组合起来,低于阈值就不组合,然后再计算组合出的词语的整个置信度,可以看出,不少词语是常见词,其余通过百度也能得知是品牌词等,通过这样计算自动为搜索算法系统的分词词典提供充足的词源,提供分词质量声明:本文仅代表作者观点,不代表本站立场。如果侵犯到您的合法权益,请联系我们删除侵权资源!如果遇到资源链接失效,请您通过评论或工单的方式通知管理员。未经允许,不得转载,本站所有资源文章禁止商业使用运营!

下载安装【程序员客栈】APP
实时对接需求、及时收发消息、丰富的开放项目需求、随时随地查看项目状态









评论