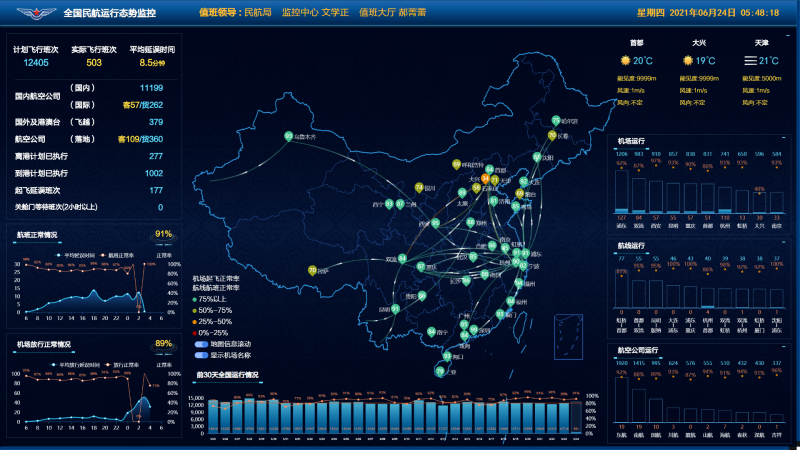
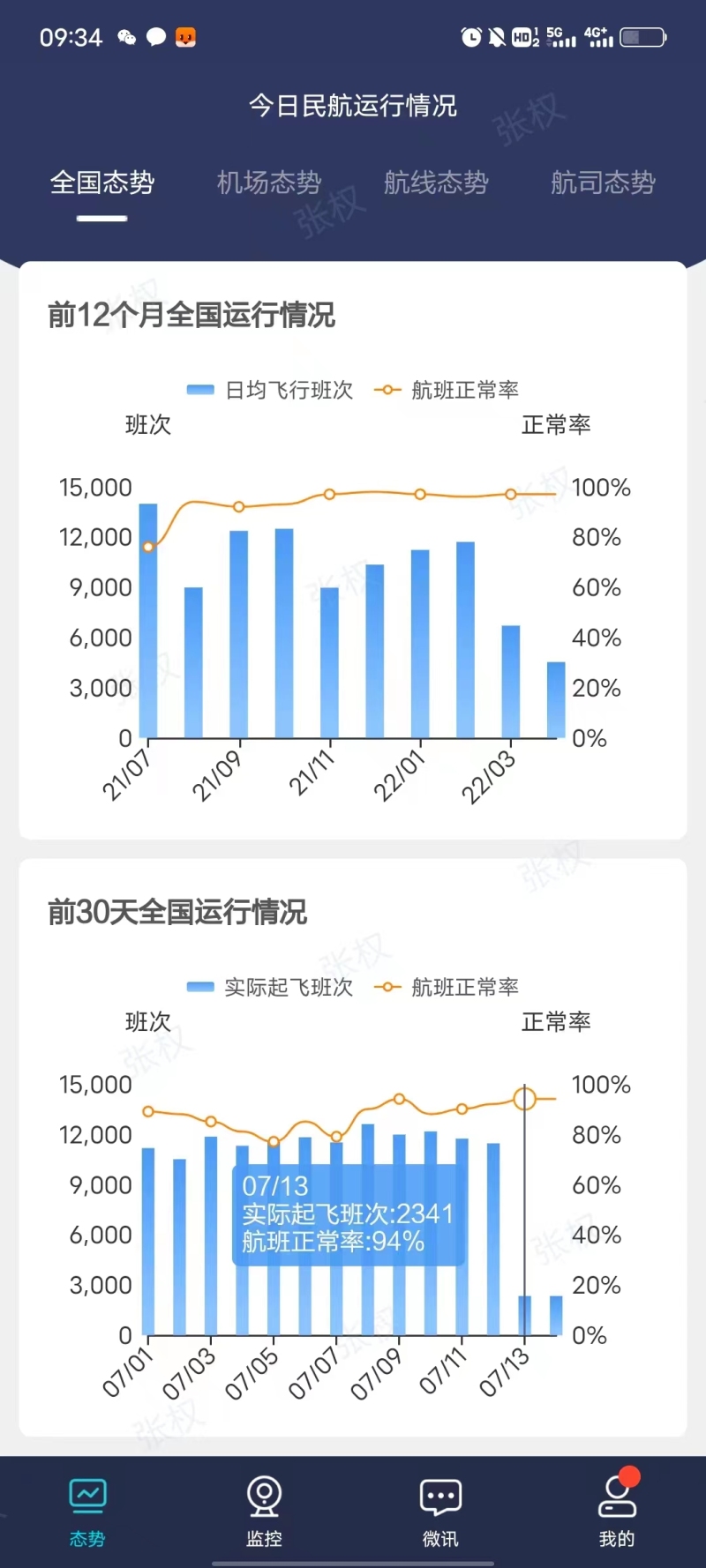
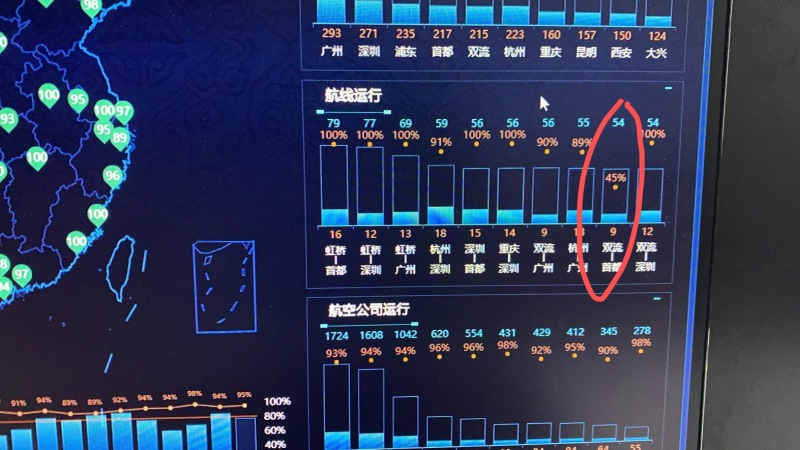
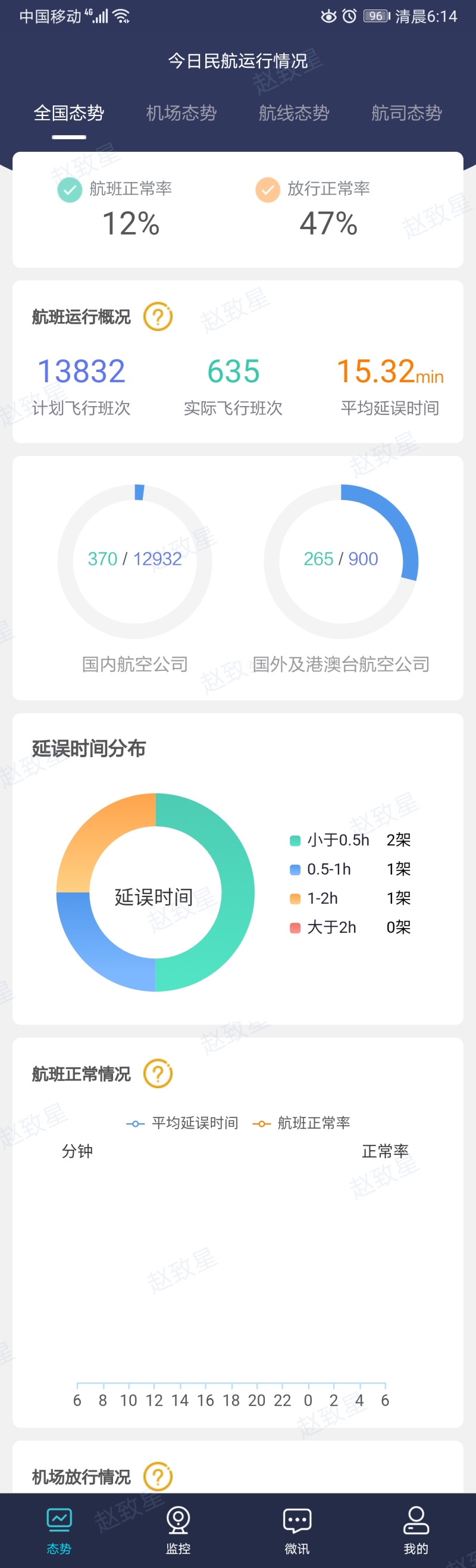
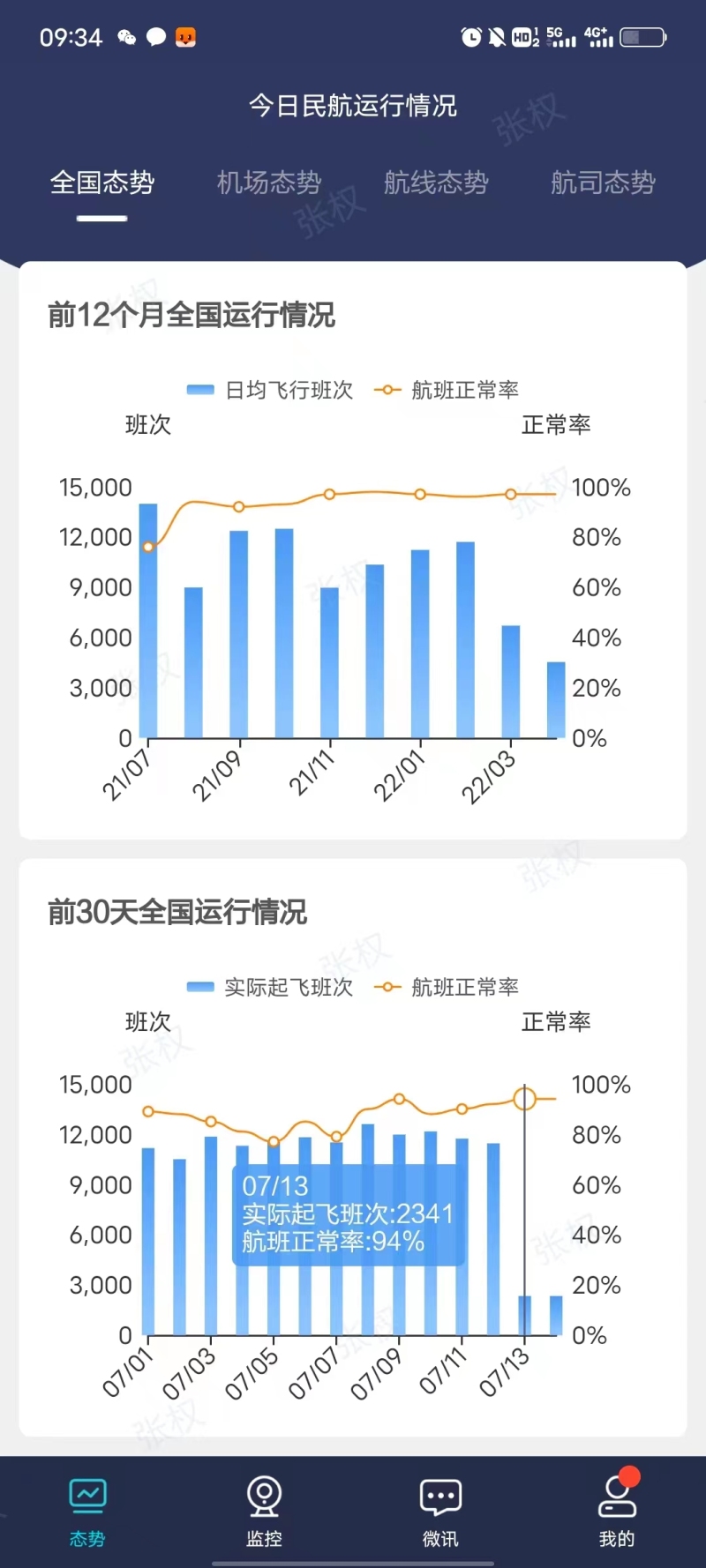
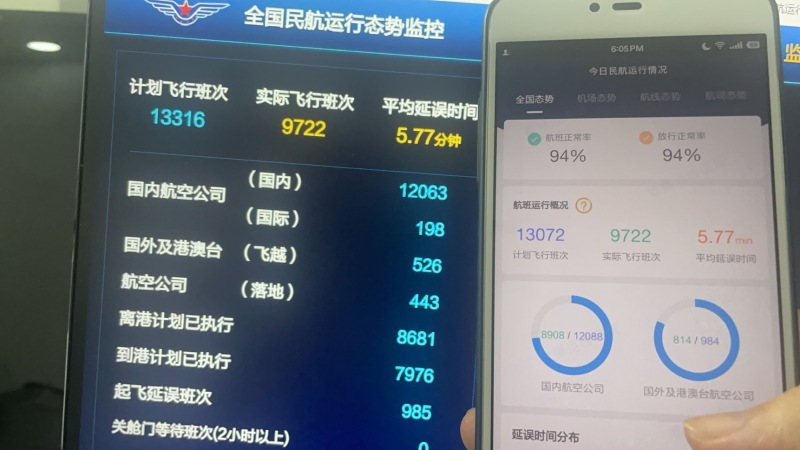
该项目是跟民航合作项目,接收的是实时飞机雷达数据和飞机航班信息,气象信息,预先飞行计 划报文等等,共计大约 20 于种数据每天的数据量大于一亿条,通过 SparkSteaming 跟前端页面的配置交 互(20 多种信息的处理方式都不一样而且会随着时间的推移有所改变,并且 sparkstreaming 任务不能中 断,所以通过前端页面的配置信息,然后 sparkStreaming 任务实时更新广播变量行相应的数据解析)完 成对实时数据进行解析->加工->融合->指标计算(以上都是实时处理并且延迟小于 1 秒)等一系列操作, 并且将雷达数据实时处理成航迹信息,延迟小于 500ms存储到 redis完成航信大厅的页面的实时飞机展示, 和存储到 hbase 中以便数据治理平台和其他系统的数据展示,将 hbase 中的数据定时清洗到 hdfs 中 parquet 格式使用 hive 进行关联,再使用 sparksql 进行数据分析,做出的数据报告存储到 MySQL 中,以便其他 子系统进行拉取。 担任角色: 大数据开发职责和成就:1. 参与产品前期大数据框架探讨,并且制定大数据框架方案。 2. 单独开发 sparkStreaming 实时任务,并且进行优化。 3. 解决 sparkstreaming 对接 kafka 偏移量问题(自定义 sparkstreaming 对接 kafka 偏移 量的读取和提交实现消费并且只消费一次) 4. 跟前端设计商定与 sparkstreaming 任务进行交互的模板。 5. 处理在 sparkstreaming 任务在不停止的情况下跟前端页面的信息交互,完成信息更新。 6. 制定 hbase 表和 rowkey,加盐,预分区等设计。 7. 对 hive 进行数仓设计(ds,dw,dws,dwd)8. 对海量数据进行离线 sparksql 分析产生数据报告。系统架构:kafka+SparkStreaming+Redis+kafka+hbase+hive+sparksql+mysql 声明:本文仅代表作者观点,不代表本站立场。如果侵犯到您的合法权益,请联系我们删除侵权资源!如果遇到资源链接失效,请您通过评论或工单的方式通知管理员。未经允许,不得转载,本站所有资源文章禁止商业使用运营!

下载安装【程序员客栈】APP
实时对接需求、及时收发消息、丰富的开放项目需求、随时随地查看项目状态









评论