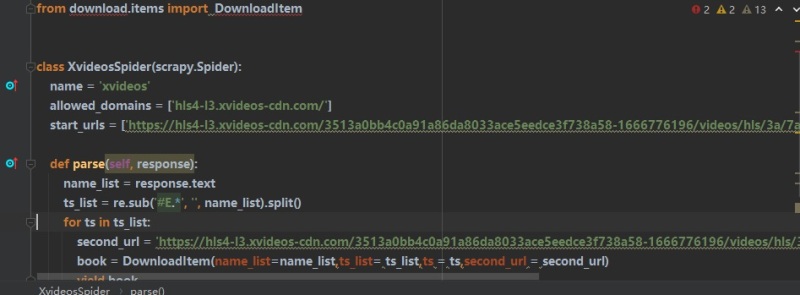
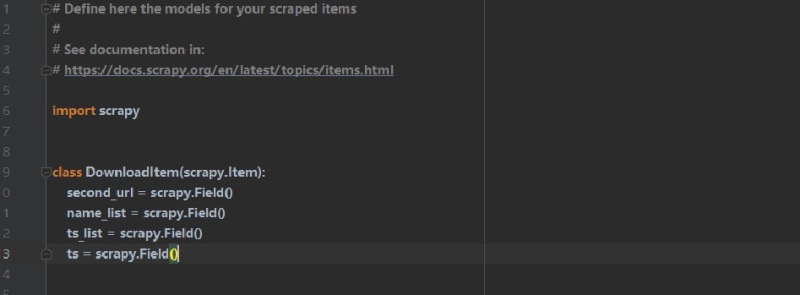
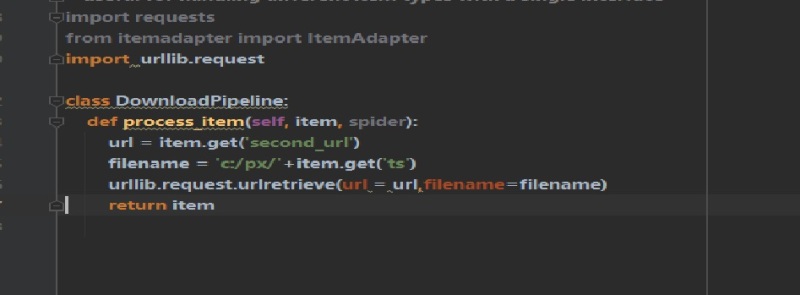
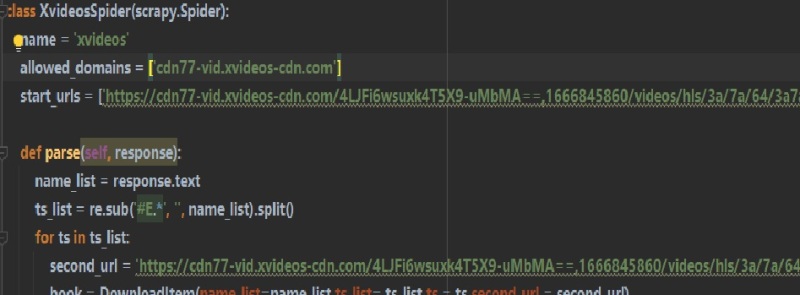
利用scrapy获取视频信息利用scrapy的自定义爬虫文件确定m3u8地址并访问获得响应数据利用循环和遍历获得存储的文件名以及需要访问的第二链接地址传递给中间件并在pipeline中进行下载由于地址变化,微调了下访问地址











评论