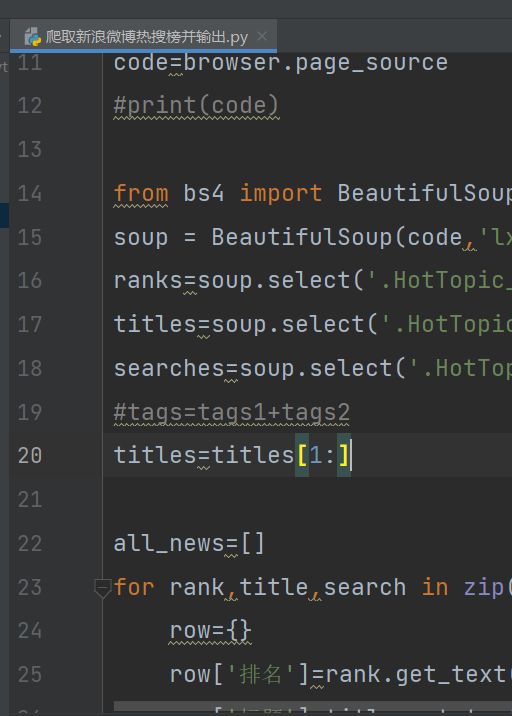
一、项目分为5个功能模块,分别实现启动模拟浏览器、模拟提取目标网站源代码、定位目标数据标签、数据清洗整理和保存数据。二、使用了python,编写全部爬虫代码,成功获取新浪热搜榜榜单(包括文字和数据)。三、难点在于新浪设置了一定反爬虫机制,利用python的selenium启动模拟浏览器声明:本文仅代表作者观点,不代表本站立场。如果侵犯到您的合法权益,请联系我们删除侵权资源!如果遇到资源链接失效,请您通过评论或工单的方式通知管理员。未经允许,不得转载,本站所有资源文章禁止商业使用运营!

下载安装【程序员客栈】APP
实时对接需求、及时收发消息、丰富的开放项目需求、随时随地查看项目状态










评论