


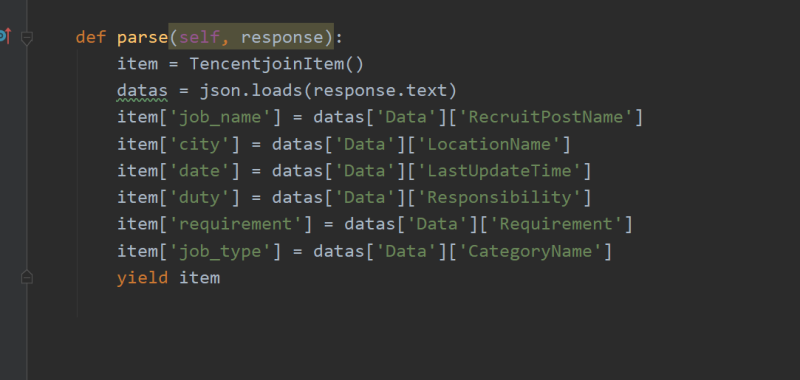
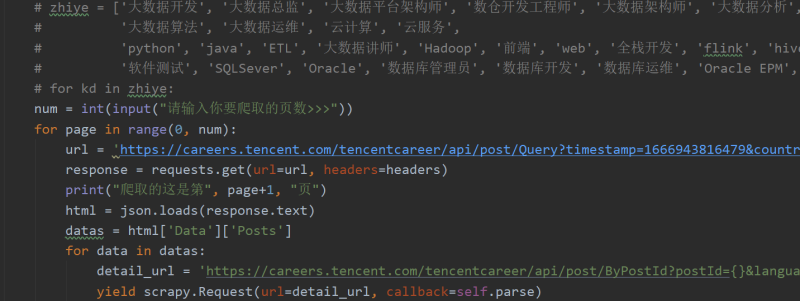
使用scrapy进行爬取,在start_requests函数内对url进行设置,使得爬取的页数可调节,还可以传入工作的类型从而实现更大范围数据的爬取,使用json.loads方法将网页数据进行爬取并且进行部分操作。使用yield返回一个Resquest接收对象为parse,再在parse中对数据进行解析和存入指向items文件中的item文件的item的对应索引下
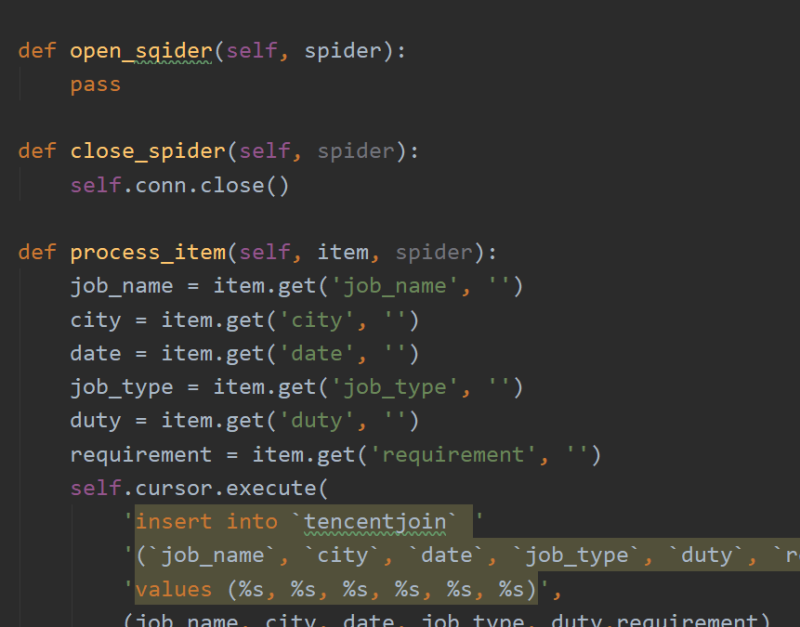
最后在pipelines中将数据持久化存储到mysql数据库中。

点击空白处退出提示



使用scrapy进行爬取,在start_requests函数内对url进行设置,使得爬取的页数可调节,还可以传入工作的类型从而实现更大范围数据的爬取,使用json.loads方法将网页数据进行爬取并且进行部分操作。使用yield返回一个Resquest接收对象为parse,再在parse中对数据进行解析和存入指向items文件中的item文件的item的对应索引下
最后在pipelines中将数据持久化存储到mysql数据库中。



评论