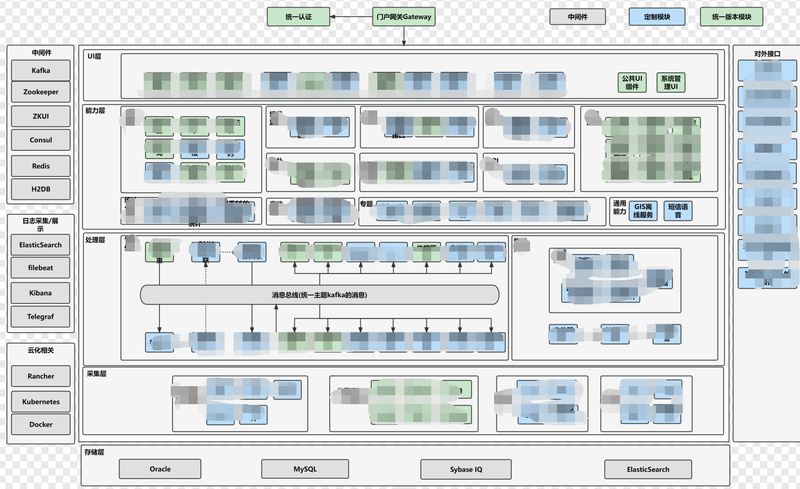
在职时主导参与的项目项目职责:1. 总体负责移动三省的故障系统的云化改造、设计和上线工作;2. 参与故障中心云化版本的总体规范编写;3. 总体牵头负责故障中心微服务化的改造、架构设计及核心组件模块的编写维护工作;4. 负责故障系统前端团队的日常管理工作,需求分析设计及拆解分配。项目实现细节、难点:1. 基于 Zookeeper 和主导自研扩展 ZKUI 开源组件构建系统配置集中管理能力;2. 系统采用前后端分离的概念,基于 node+angular/vue+bootstrap+webpack 构建前端UI能力;3. 基于开源的 SpringCloud Gateway 主导自研扩展可界面配置化的门户网关组件(包括路由、灰度发布、鉴权、 api 垂直权限管理、 iphash 等功能特性);4. 使用 Kafka 解耦系统内各异构模块,降低系统内部耦合度,构建集群化的模块部署,并主导封装的统一消息处理辅助库;5. 使用 Redis 缓存热点数据缓解数据库压力,并基于 Redis 封装分布式锁等场景;6. 搭建统一的海量告警(日均 1000w ,每条 10k )、性能数据( 2000+ 指标)的快速搜索和统计分析库,并基于系统高可用需要封装 ES 高可用 api ;7. 系统所有模块均做了云化改造,基于 rancher+k8s+docker+harbor 构建故障中心应用容器化平台(管理 200 ~ 500+ vm 节点);8. 基于 ES+filebeat+Kibana +分布式存储实现容器化应用的统一日志搜集和管理平台(日均 250G 日志);9. 使用 saltstack 搭建批量配置和部署平台( vm 配置调整、应用软件配置安装、自动化运维工作);10. 自研agent类库构建系统IT监控指标采集和分析展示,提供系统预警和优化决策;11. 难点1:系统业务量大,每天告警量差不多在300w-1000w左右,每天接入的性能指标数量量在几百G左右,业务复杂系统稳定性要求高,需要7*24小时不间断运行,系统模块多消息流复杂,消息实时处理时延要求高;12. 难点2:系统改动巨大,近乎从头到尾做了全新的改造,原系统所有C++模块全部改造适配成java版本,系统间模块调用全由同步的corba(RPC)方式调用切换成异步(kafka)方式,并将单体式系统按照业务解耦拆分成了各个独立的微服务能力,并对前后端做彻底分离,前端也有老的技术栈(struts+jsp)改造成了h5+angulajs/vue+webpack的纯前端模式。13. 难点3:系统运维体系的改变,原先采用的都是基于shell脚本和监控短信的方式对系统做维护,系统升级也基本都是纯手工传代码的方式。改造后从监控体系做了完全改造自研了一套完整监控体系(从应用、中间件、主机),运维人员只需在维护页面配置配置即可快速完成系统的监控规则;14. 难点4:团队组织的巨变,原系统开发模式功能一般都由一个人完成,先系统按照业务、前后端进行拆分解耦后前端、能力层、处理层都需要专职的人员进行开发维护,分工更加精细开发效率自然也就更加高效。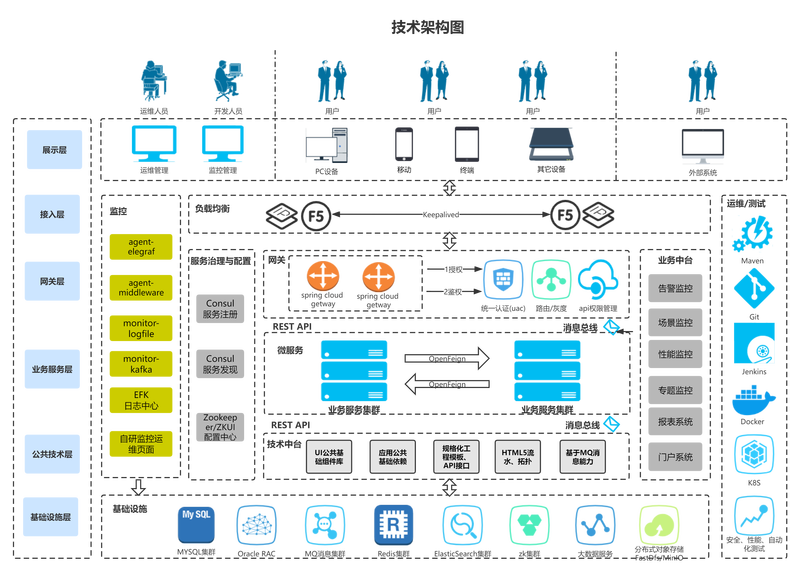
声明:本文仅代表作者观点,不代表本站立场。如果侵犯到您的合法权益,请联系我们删除侵权资源!如果遇到资源链接失效,请您通过评论或工单的方式通知管理员。未经允许,不得转载,本站所有资源文章禁止商业使用运营!

下载安装【程序员客栈】APP
实时对接需求、及时收发消息、丰富的开放项目需求、随时随地查看项目状态









评论