





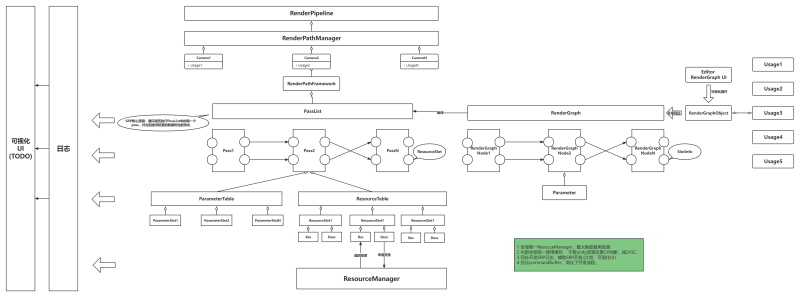
这是一个由Unity RenderGraph的二次开发,将渲染管线可视化后可快速的自定义自己的渲染管线。我在这个项目中担任的是处理RenderGraph的解析和相关的运行,日志以及RenderTexture的管理。以下链接是官方公布技术分享https://developer.unity.cn/projects/612741adedbc2a484ade66de
RenderGraph的简介: RenderGraph是一个可视化的工具,我们可以创建相应自定义的节点和连线,所以我们将Scripatble Render Pipeline的各个feature映射到节点(比如Draw Opaque,Draw Transparency,TAA, DOF等),将各个feature的依赖关系用连线表示,这样我们得到一个有向的拓扑结构,而最终我们需要从这个拓扑结构中,在满足现有依赖关系的情况下得到一个节点队列,这个队列将是运行时各个feature的执行队列。因为渲染管线的一个特性,就是只有一个出口。所以在解析阶段,我从出口节点出发逆向遍历,这样不但可以剔除掉无用的节点,还可能得到一个满足依赖关系的执行队列。
RenderGraph的问题: 以上得到的这个执行队列并不是最优的,因为拓扑是网状的,所以这个队列最多有N!种可能性。每一种可能都会导致RenderTexuture的切换次数变化,而RT的切换会在手机端影响渲染性能(这是由手机芯片的硬件设计导致)。所以我们必须找一个一条RT切换最少的队列。要完成这个我们需要遍历所有可能性,这时我们面临一个问题,就是在N!的复杂度下,当节点过多时,计算变的不可能完成。我们测试当节点到达30个时,基本需要几个小时了。而如果再多加一个,很可能需要几天。而我们希望是要100个以应对未来和PC上的需求。
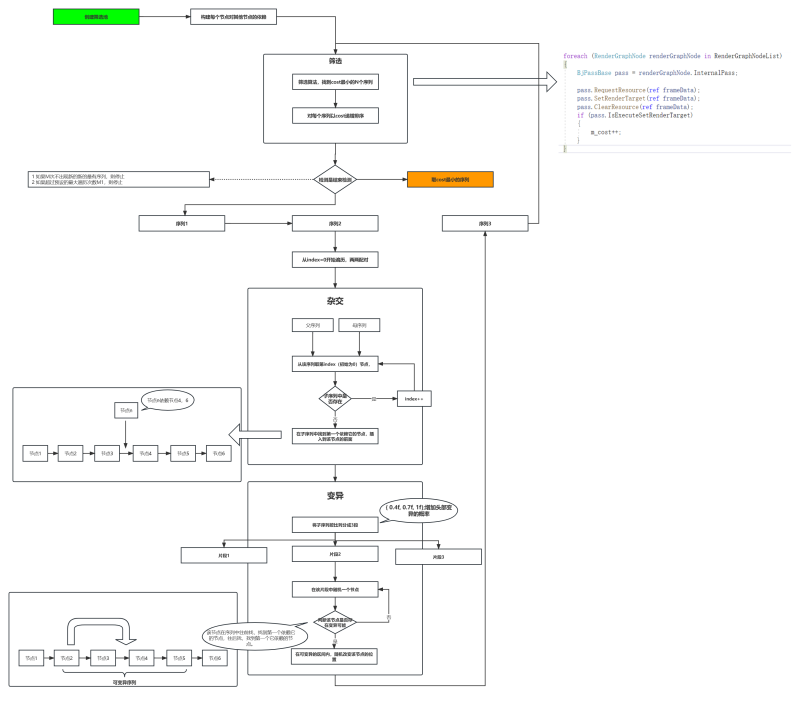
RenderGraph的解决:这里我试图在编译节点剔除掉一些可以被忽略的节点,但是在测试当前最复杂的图时,依然非常吃力。所以我跳出现有思维,在一篇GDC的文章启发下,我找到了用基因算法去解决这个问题。基因算法是一个相对成熟的AI算法,可以解决在海量不可计算的情况下,找到一个相对的最优解。所以我先用拓扑遍历得到M条可能的序列,在满足现有依赖关系的情况下,将现有的队列两两配对,完成了两条序列的杂交和变异。在得到的新的队列和原有的队列中找到cost最少M条队列。然后重复迭代。在迭代K=100代的时候,基本可以找到一个不错的方案。这里的M和K的参数越大,结果越好。在这种算法下,40个节点的图基本在毫秒界别就能完成计算,即使扩展到100个,也能在几秒内完成计算。
RenderTexture的管理:在运行阶段,我们需要为每个feature分配RT,项目曾今用静态的方式去处理这个问题,结果是RT过大,因为很多情况下RT是可以复用,比如featureA已经执行完毕,它的临时RT已经不再使用,这张RT可以被具有相同的参数的featureB使用。我在处理这个问题时,用了一个RT的缓存池子,并根据RT的参数去生成一个HashCode(该算法在Unity源码中大量使用,用于区分对象是否发生改变),用这个HashCode做为Key去缓存池申请RT。这样就可以实现最大限度的优化RT,且因为全局唯一,所以不同的view下的RenderGraph可以共享使用。
日志:在RenderGraph开发阶段,我们会面临一个问题,就是调试异常麻烦,特别RT被设置错误时,效果出错且没有任何报错和异常的日志。所以我们并不能借助Unity FrameDebug和RenderDoc去定位我们开发的RenderGraph对应的管线的问题。因此我在管线中加了大量的日志,通过不同的类型记录不同的参数(该做法参考Unity的日志系统),该功能虽然代码里巨大,但是最终我会得到一份管线详细的数据,包括各个feature的执行顺序,RT使用情况,Load/Store Action参数,甚至到每个SRP API的调用。最终这个日志可以大大提高现有代码的调试且可以提供一份详细的数据记录,未来可以生成一份可视化的调试工具,类似FrameDebug。
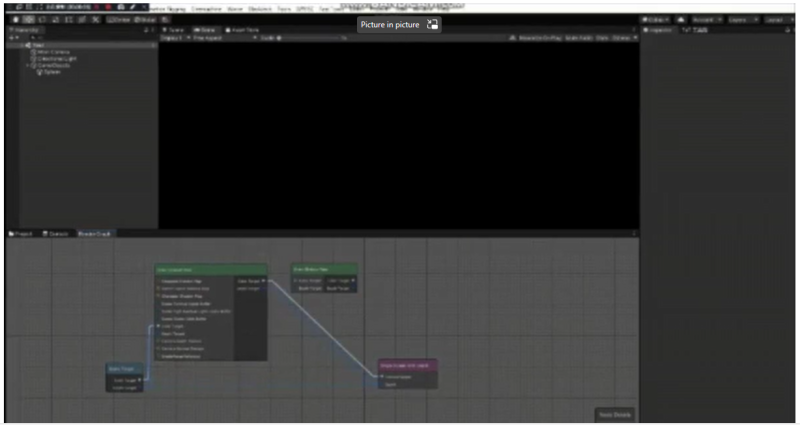

点击空白处退出提示



评论