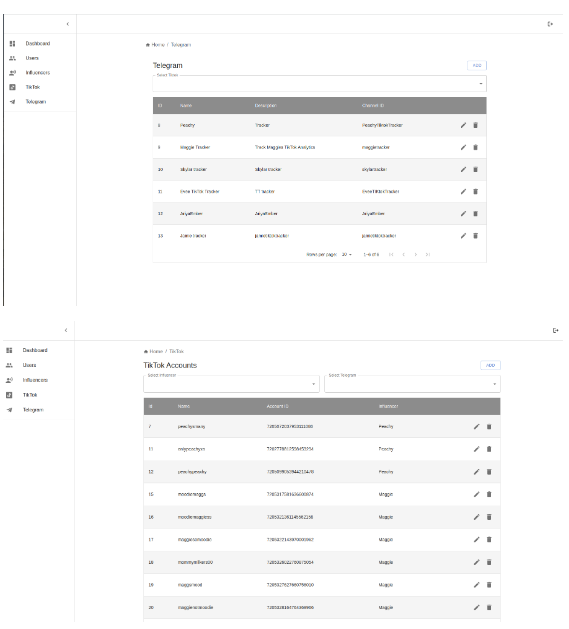
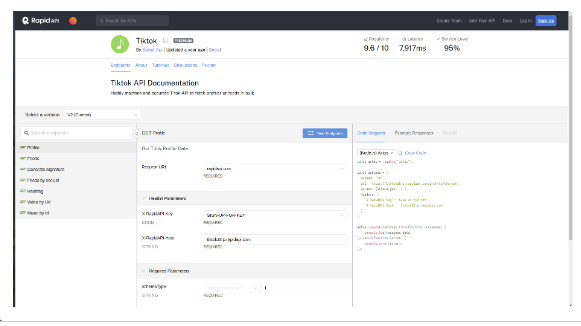
该项目是我开发的一款利用Selenium和Scrapy进行网络爬虫的工具,主要用于从抖音网站抓取数据并将这些数据发送到电报频道。以下是对项目的详细描述:1. **网络爬虫技术**:Selenium和Scrapy是我用来从网站获取数据的两种主要工具。Selenium是一个用于自动化浏览器操作的工具,它可以模拟真实用户行为,比如点击按钮、输入文本等。Scrapy则是一个用于网页抓取和数据提取的开源Python框架,能够处理HTTP请求,解析HTML文本等。2. **数据源**:本项目主要从抖音这一短视频分享平台获取数据。抖音网站上有丰富的用户生成内容,包括各种短视频,这为我们提供了大量的数据。3. **数据提取**:我设计了一套抓取策略,可以从抖音网站上抓取需要的数据,比如视频标题、视频链接、视频标签等。4. **数据传输**:抓取完成后,我将数据发送到电报频道。电报是一种即时通讯应用,支持发送文本、图片、视频等多种类型的消息。5. **服务运行**:为了使抓取服务可以持续运行,我部署了一套自动化系统,当新的数据出现在抖音网站上时,系统会自动启动抓取程序,并将新数据发送到电报频道。这个项目不仅提高了我的网络爬虫技术,同时也增强了我在数据处理和自动化系统部署方面的经验。声明:本文仅代表作者观点,不代表本站立场。如果侵犯到您的合法权益,请联系我们删除侵权资源!如果遇到资源链接失效,请您通过评论或工单的方式通知管理员。未经允许,不得转载,本站所有资源文章禁止商业使用运营!

下载安装【程序员客栈】APP
实时对接需求、及时收发消息、丰富的开放项目需求、随时随地查看项目状态


 1
1




评论