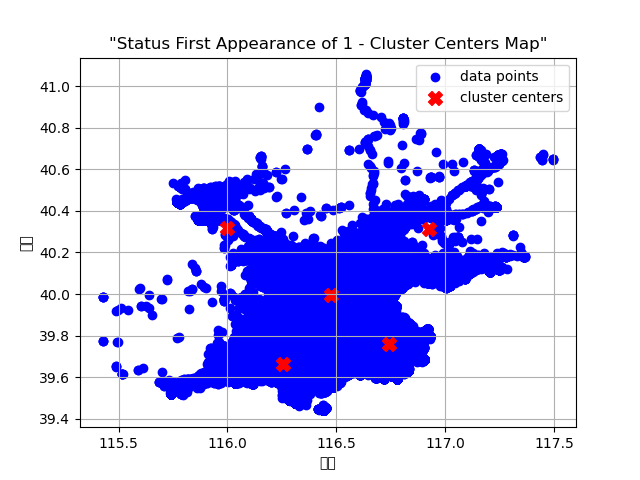
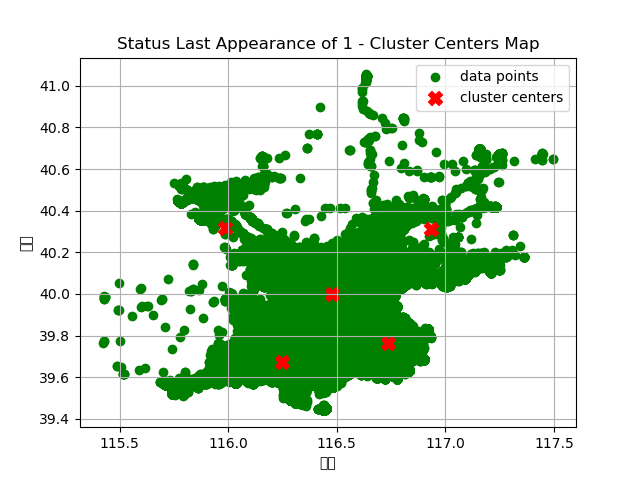
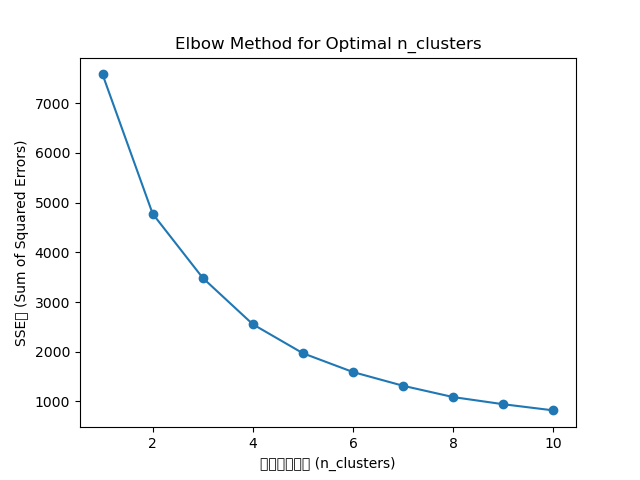
1. 项目功能分为:数据预处理、坐标建模、轨迹分析、坐标聚类、生成聚类中心图和输出时间及位置信息。该项目的输入包括车辆ID、经纬度、方向、速度、状态(0:空载、1:有载客)、数据发送时间(年月日时分秒)、数据接收时间、行政区号和具体位置等信息,数据格式为.txt文件。该项目的目的是根据每辆车的轨迹信息,时间先后,及状态(有无载客)来确定上下车集中的位置和时间,本质上是实现坐标点的聚类。使用者可以修改输入数据(使用前需要将.txt格式转为.csv格式),替换和修改聚类算法,找到更加精确的聚类中心,提高预测精度。本项目中确定聚类中心的距离指标是欧氏距离,使用者可以根据实际需要修改为其他距离指标(如:曼哈顿距离)2. 本项目的难点在于数据筛选、坐标建模以及聚类中心的确定。将txt文件转为csv文件便于进行后续的数据处理,该数据集包含20万条车辆信息,包括:车辆ID、经纬度、方向、速度、状态(0:空载、1:有载客)、数据发送时间(年月日时分秒)、数据接收时间、车辆类型(全为0:出租车)、行政区号和具体位置,其中与项目相关的数据包括:车辆ID、经纬度(上下车点)、状态、数据发送时间(将该时间视为该车当时所处的时间点)、行政区号和具体位置。将经纬度转为位置坐标,根据车辆ID分组,然后按照时间先后进行排序,查看每辆车的运行轨迹以及载客状态的变化,根据肘部原则确定聚类中心的个数,使用K-means算法确定聚类中心的位置,生成聚类中心图,然后找到距离聚类中心最近的点,将该点的时间和位置信息(行政区号和具体位置)打印为一个文本声明:本文仅代表作者观点,不代表本站立场。如果侵犯到您的合法权益,请联系我们删除侵权资源!如果遇到资源链接失效,请您通过评论或工单的方式通知管理员。未经允许,不得转载,本站所有资源文章禁止商业使用运营!

下载安装【程序员客栈】APP
实时对接需求、及时收发消息、丰富的开放项目需求、随时随地查看项目状态


 2
2





评论