





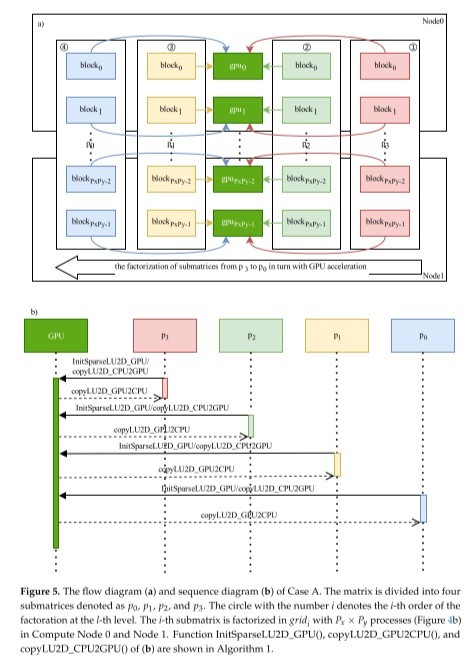
利用GPU加速并行方法对大型稀疏矩阵进行LU分解需要大量的计算资源,特别是当矩阵的规模大到GPU内存不能将所有数据装入时,线性方程组的求解就不能进行了。本文提出一种基于LU分解的超大型稀疏矩阵的GPU加速算法“SuperLU3D_Alternate”。该算法是基于SuperLU3D算法的改进算法。SuperLU3D算法在有限的GPU资源下,解决不了超大型稀疏矩阵的LU分解问题。同时,SuperLU3D算法在计算过程中有大量数据的非阻塞通信,可能出现超过集群通信缓存限制导致内存溢出,从而无法稳定工作。为了解决这两个问题,SuperLU3D_Alternate算法利用矩阵列消去树将矩阵分成多个子矩阵,将每个子矩阵当成一个待处理的任务轮流执行,按预定顺序调用GPU进行LU分解,计算过程中把GPU中间结果保存在主机内存或硬盘中,计算结束后在各个子矩阵块之间进行数据交换并组装。算法“SuperLU3D_Alternate”依据硬件资源情况,细分三种情况来设计算法:(1)主机内存大小同时满足LU分解所需内存和GPU矩阵数据保存到主机的内存之和,子矩阵数据所在进程与绑定的GPU在同一节点上;(2)GPU节点主机内存不能满足LU分解所需内存,部分子矩阵数据保存在不带GPU的节点主机内存中;(3)进行LU分解需要的内存大于集群的总内存。SuperLU3D_Alternate的时间复杂度、空间复杂度分析和实例验证结果表明,在计算资源足够的情况下,其计算效率也能够媲美SuperLU3D算法。总体上实验矩阵规模越大,SuperLU3D_Alternate算法越有优势。而且,在GPU显存不足以对整个矩阵进行LU分解的情况下,仍然可以利用集群主机内存或者硬盘保存中间计算过程的数据,以此来解决大规模矩阵LU分解问题。同时,该算法也减少大量数据在进程之间的传输,以防止超过集群MPI数据传输的缓存上限,提高了程序的稳定性。


点击空白处退出提示



评论