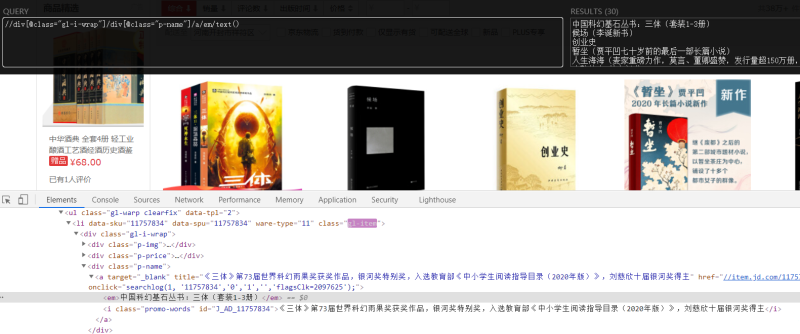
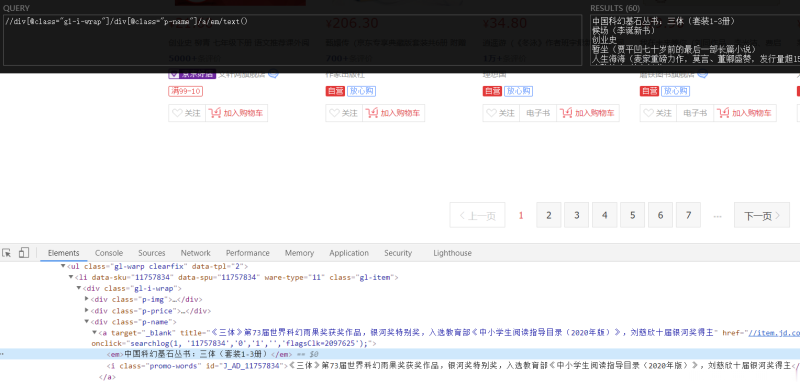
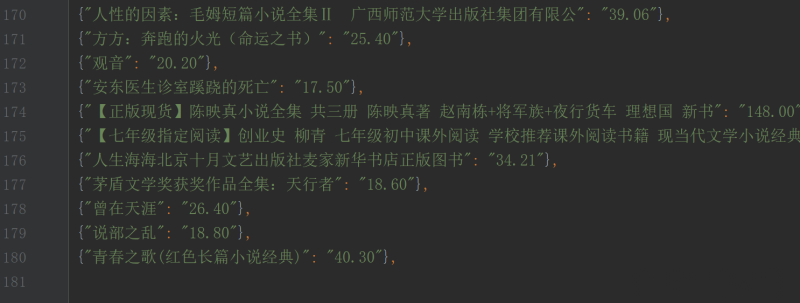
项目简介:该项目旨在通过爬虫技术获取京东图书类商品的相关数据。通过对京东网站的爬取,获取到图书的名称、作者、出版社、价格、评论等信息。项目分为以下模块:网页解析模块:通过使用 Selenium 进行 HTTP 请求解析网页结构,提取所需的信息。数据存储模块:将爬取到的数据存储到数据库或文件中,以便后续处理和分析。反爬虫处理模块:由于京东网站可能会采取反爬虫措施,需要编写相应的代码来应对,如设置合适的请求头信息、使用代理IP等。并发控制模块:为了提高爬取效率,可以使用多线程或异步编程技术实现并发控制,同时发送多个请求并处理响应。我负责的内容包括:项目规划和设计:确定项目的需求和目标,分析数据结构和流程,制定爬虫策略和算法。网页解析模块的实现:编写网页解析代码,根据需求提取出图书的相关信息。数据存储模块的实现:选择合适的数据库或文件格式,编写代码将爬取到的数据进行存储。反爬虫处理模块的实现:分析反爬虫机制,编写相应的代码来绕过反爬虫措施。并发控制模块的实现:根据实际需求选择合适的并发技术,编写代码实现并发控制。项目的难点及解决方法:反爬虫机制:京东网站可能采取IP封禁、验证码等手段进行反爬虫,可以使用代理IP池、自动识别验证码等技术来应对。动态网页加载:部分图书信息可能通过Ajax或其他动态加载方式呈现,可以使用Selenium等工具模拟浏览器行为,获取完整的页面数据。大规模数据处理:京东图书数据庞大,需要考虑如何高效地处理大量数据,可以使用分布式爬虫、多线程或异步编程等技术来提高效率。数据一致性和准确性:由于网页结构可能变化,需要定期检查和更新解析代码,保证爬取的数据准确且一致。京东网站解析的复杂性:使用传统的解析库难以正确地提取所需的信息。使用Selenium以选择元素并提取数据。总体来说,该项目涉及到网页解析、数据存储、反爬虫处理和并发控制等方面,需要综合运用多种技术来完成任务。声明:本文仅代表作者观点,不代表本站立场。如果侵犯到您的合法权益,请联系我们删除侵权资源!如果遇到资源链接失效,请您通过评论或工单的方式通知管理员。未经允许,不得转载,本站所有资源文章禁止商业使用运营!

下载安装【程序员客栈】APP
实时对接需求、及时收发消息、丰富的开放项目需求、随时随地查看项目状态









评论