本项目向社区提供中文对话模型Linly-ChatFlow、中文基础模型Linly-Chinese-LLaMA及其训练数据。模型基于 TencentPretrain 预训练框架实现,在32*A100GPU上全参数训练(Full-tuning),将陆续开放7B、13B、33B、65B规模的中文模型权重。中文基础模型以LLaMA为底座,利用中文和中英平行增量预训练,将它在英文上强大语言能力迁移到中文上。进一步,项目汇总了目前公开的多语言指令数据,对中文模型进行了大规模指令跟随训练,实现了Linly-ChatFlow对话模型。此外,本项目还将公开从头训练的 Linly-Chinese-OpenLLaMA 模型,在1TB中英文语料预训练,针对中文优化使用字词结合tokenizer,模型将以Apache2.0协议公开。项目特点通过Full-tuning(全参数训练)获得中文LLaMA模型,提供TencentPretrain与HuggingFace版本汇总中文开源社区指令数据,提供目前最大的中文LLaMA模型模型细节公开可复现,提供数据准备、模型训练和模型评估完整流程代码多种量化方案,支持CUDA和边缘设备部署推理基于公开数据从头训练Chinese-OpenLLaMA,针对中文优化字词结合tokenizer(进行中)中文预训练语料 | 中文指令精调数据集 | 模型量化部署 | 领域微调示例
模型下载使用须知模型权重基于 GNUGeneralPublicLicensev3.0 协议,仅供研究使用,不能用于商业目的。请确认在已获得许可的前提下使用本仓库中的模型。7B:基础模型Linly-Chinese-LLaMA-7B| 对话模型Linly-ChatFlow-7B| int4量化版本Linly-ChatFlow13B:基础模型Linly-Chinese-LLaMA-13B| 对话模型Linly-ChatFlow-13B33B:33B基础模型65B:训练中HuggingFace模型7B基础模型 | 13B基础模型 | 33B基础模型7B对话模型 | 13B对话模型训练情况模型仍在迭代中,本项目定期更新模型权重。局限性Linly-ChatFlow完全基于社区开放语料训练,内容未经人工修正。受限于模型和训练数据规模,Linly-ChatFlow目前的语言能力较弱,仍在不断提升中。开发团队表示已经观察到Linly-ChatFlow在多轮对话、逻辑推理、知识问答等场景具有明显缺陷,也可能产生带有偏见或有害内容。此外,由于增量训练和指令精调阶段使用了相同的预训练目标(causalLM),发现在一些情况下模型会续写指令(例如,语义理解-Q4-13B),计划将在下个版本解决这一问题。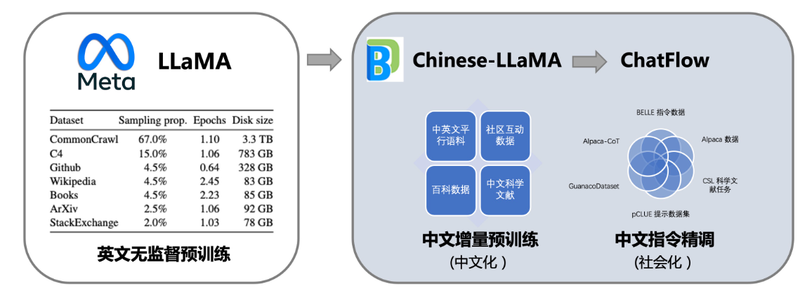

声明:本文仅代表作者观点,不代表本站立场。如果侵犯到您的合法权益,请联系我们删除侵权资源!如果遇到资源链接失效,请您通过评论或工单的方式通知管理员。未经允许,不得转载,本站所有资源文章禁止商业使用运营!

下载安装【程序员客栈】APP
实时对接需求、及时收发消息、丰富的开放项目需求、随时随地查看项目状态









评论