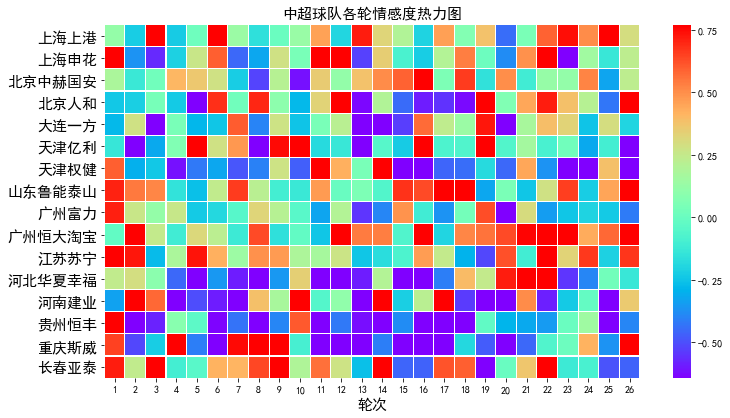
HarvestText是一个专注无(弱)监督方法,能够整合领域知识(如类型,别名)对特定领域文本进行简单高效地处理和分析的库。适用于许多文本预处理和初步探索性分析任务,在小说分析,网络文本,专业文献等领域都有潜在应用价值。使用案例:分析《三国演义》中的社交网络(实体分词,文本摘要,关系网络等) 2018中超舆情展示系统(实体分词,情感分析,新词发现[辅助绰号识别]等)相关文章:一文看评论里的中超风云 【注:本库仅完成实体分词和情感分析,可视化使用matplotlib】具体功能如下:基本处理精细分词分句可包含指定词和类别的分词。充分考虑省略号,双引号等特殊标点的分句。文本清洗处理URL,email,微博等文本中的特殊符号和格式,去除所有标点等实体链接把别名,缩写与他们的标准名联系起来。命名实体识别找到一句句子中的人名,地名,机构名等命名实体。实体别名自动识别(更新!)从大量文本中自动识别出实体及其可能别名,直接用于实体链接。例子见这里依存句法分析分析语句中各个词语(包括链接到的实体)的主谓宾语修饰等语法关系,内置资源通用停用词,通用情感词,IT、财经、饮食、法律等领域词典。可直接用于以上任务。信息检索统计特定实体出现的位置,次数等。新词发现利用统计规律(或规则)发现语料中可能会被传统分词遗漏的特殊词汇。也便于从文本中快速筛选出关键词。字符拼音纠错(调整)把语句中有可能是已知实体的错误拼写(误差一个字符或拼音)的词语链接到对应实体。自动分段使用TextTiling算法,对没有分段的文本自动分段,或者基于已有段落进一步组织/重新分段存取消除可以本地保存模型再读取复用,也可以消除当前模型的记录。英语支持本库主要旨在支持对中文的数据挖掘,但是加入了包括情感分析在内的少量英语支持高层应用情感分析给出少量种子词(通用的褒贬义词语),得到语料中各个词语和语段的褒贬度。关系网络利用共现关系,获得关键词之间的网络。或者以一个给定词语为中心,探索与其相关的词语网络。文本摘要基于Textrank算法,得到一系列句子中的代表性句子。关键词抽取基于Textrank,tfidf等算法,获得一段文本中的关键词事实抽取利用句法分析,提取可能表示事件的三元组。简易问答系统从三元组中建立知识图谱并应用于问答,可以定制一些问题模板。效果有待提升,仅作为示例。用法首先安装,使用pippipinstall--upgradeharvesttext或进入setup.py所在目录,然后命令行:pythonsetup.pyinstall随后在代码中:fromharvesttextimportHarvestTextht=HarvestText()即可调用本库的功能接口。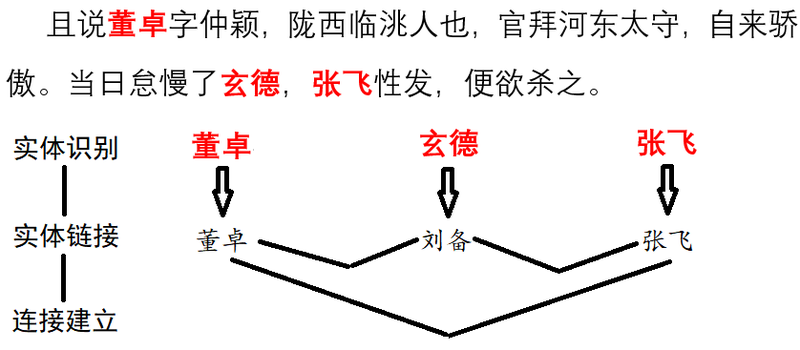
声明:本文仅代表作者观点,不代表本站立场。如果侵犯到您的合法权益,请联系我们删除侵权资源!如果遇到资源链接失效,请您通过评论或工单的方式通知管理员。未经允许,不得转载,本站所有资源文章禁止商业使用运营!

下载安装【程序员客栈】APP
实时对接需求、及时收发消息、丰富的开放项目需求、随时随地查看项目状态





 2021年10月17日
2021年10月17日


评论