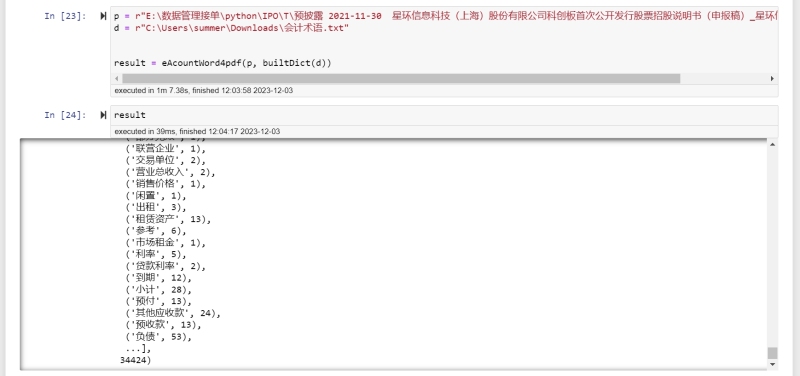
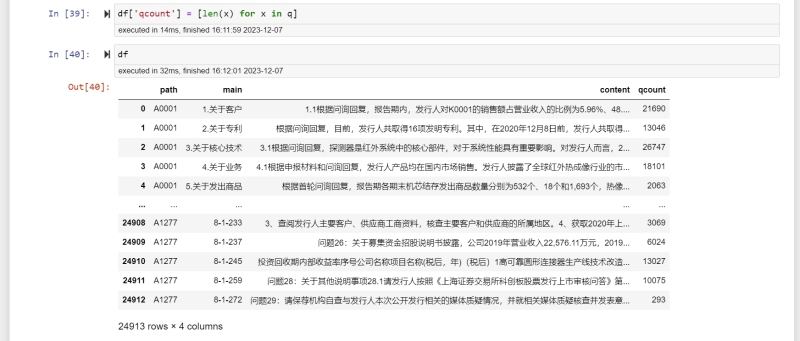
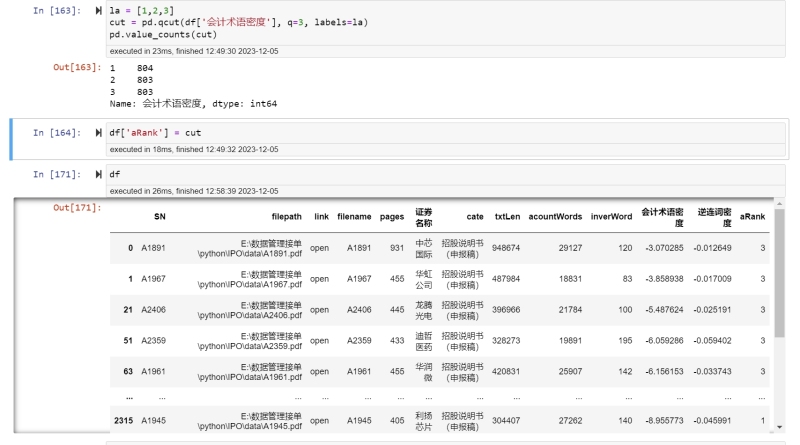
内容包括:1. 对上市公司IPO审核问询回复函、招股说明书PDF格式原始文件(11000个)进行目标文件锁定。二进制去重,并基于目标公司名单,及关键字,筛选出目标文件2490。2. 使用python模块plumber抽提PDF中的文本,表格和图片信息,进行数据清洗与结构化。3. 读取文本目录,将文章分割为问题块及回答块,分别统计字符数,评估问询函有效性。4. 采用自然语言处理框架中的Jieba分词技术对文本内容进行切割,基于HMM模型和 Viterbia算法进行预测分词,将分词结果与《灵格斯汉英会计词典会计术语词典》进行比对,统计会计词汇出现次数,计算会计术语密度。5. 以(现代汉语篇章中的连接成分》逆接连接成分为基础构律词典,使用re模块将每个逆接词作为正则表达式的pattern去匹配全文内容,统计逆接词出现的总次数,计算逆连词密度。6. 将PDF中提取的表格与图片信息,折算为行数,计算可视化信息占比。7. 使用pandas综合多个指标,分箱评级,得出文章可读性分数。声明:本文仅代表作者观点,不代表本站立场。如果侵犯到您的合法权益,请联系我们删除侵权资源!如果遇到资源链接失效,请您通过评论或工单的方式通知管理员。未经允许,不得转载,本站所有资源文章禁止商业使用运营!

下载安装【程序员客栈】APP
实时对接需求、及时收发消息、丰富的开放项目需求、随时随地查看项目状态








评论