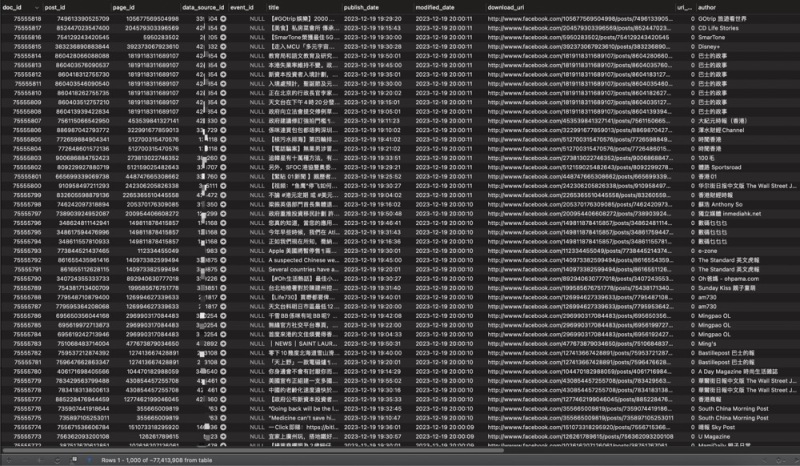
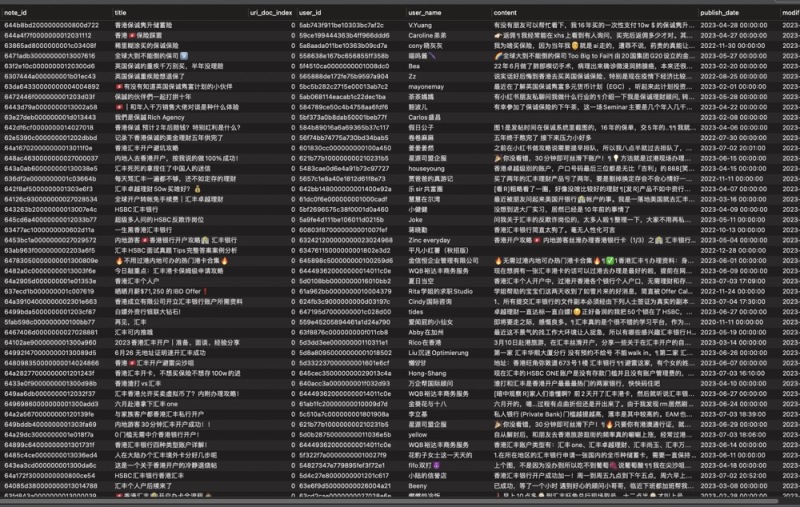
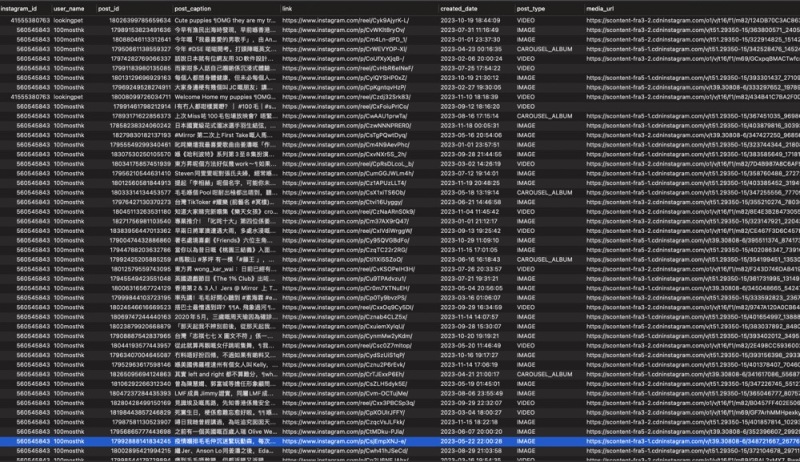
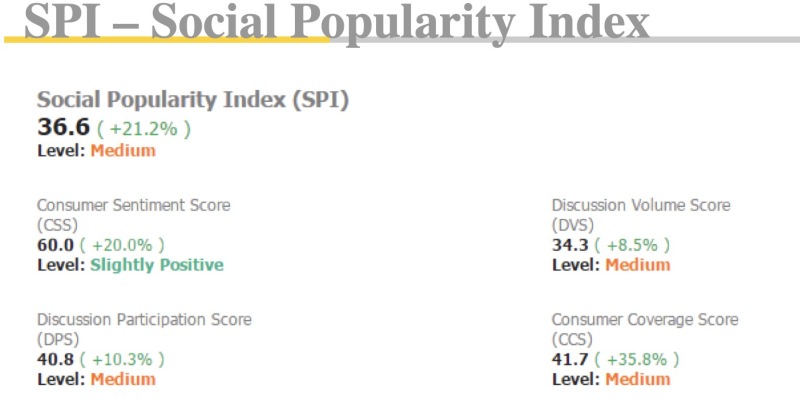
项目功能模块概述:数据抓取模块: 实现从各种互联网源头如论坛、博客、新闻等抓取海量数据。情报展示模块: 将抓取到的数据按照企业需求进行分析和展示,提供直观的情报,帮助企业制定竞争策略。多源数据解析模块: 利用Java的htmlparser库进行html解析,提取关键信息,同时通过Python、Selenium、XPath等技术爬取Facebook、Weibo、小红薯、Google、Instagram、Twitter等平台数据。Linux服务器支持: 构建强大的Linux服务器群,用于存储和处理海量数据。用户实现的功能:使用者可以通过系统从互联网各个渠道获取大量商业价值的情报数据,系统对数据进行解析和展示,帮助企业了解竞争环境,优化竞争策略。我的贡献和技术栈:负责模块: 我独立负责了从论坛和博客中抓取数据的模块,进行了grasper的优化,同时负责Linux服务器的部署,通过Shell脚本实现了持续部署能力。使用技术栈: 项目核心技术包括Java的htmlparser库用于HTML解析,以及Python的Selenium、XPath解析等技术用于多源数据的爬取。最终成果: 我的工作保障了系统能够高效、稳定地从各个互联网渠道抓取大量商业价值的数据。通过优化grasper和实现持续部署,提高了系统的抓取效率和可维护性。我在项目中的工作为企业提供了强有力的竞争情报支持,使其在商业竞争中保持竞争优势。截图中是数据展示声明:本文仅代表作者观点,不代表本站立场。如果侵犯到您的合法权益,请联系我们删除侵权资源!如果遇到资源链接失效,请您通过评论或工单的方式通知管理员。未经允许,不得转载,本站所有资源文章禁止商业使用运营!

下载安装【程序员客栈】APP
实时对接需求、及时收发消息、丰富的开放项目需求、随时随地查看项目状态









评论