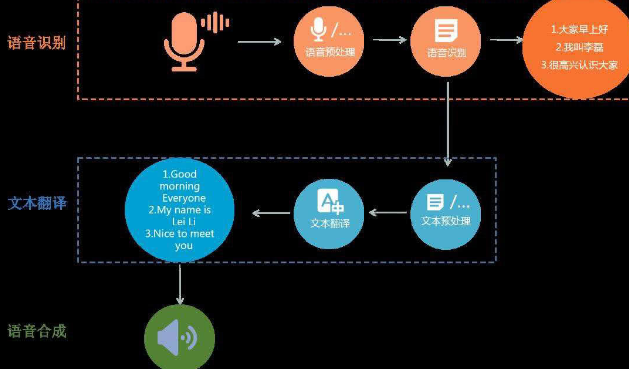
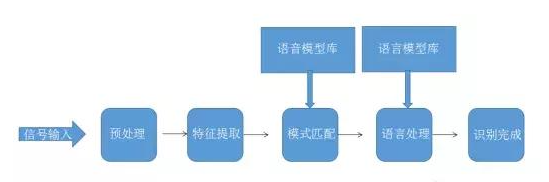
基于人工智能的语音识别和处理项目包括以下功能模块:1. **语音采集与预处理**: - 语音采集:负责收集语音数据。 - 预处理:包括去噪、归一化、切割等,为后续特征提取做准备。2. **特征提取**: - 从预处理后的语音信号中提取特征,如MFCC、PLP等。3. **模型训练与优化**: - 使用标注好的训练数据训练语音识别模型。 - 优化模型参数,提高识别准确率。4. **解码与后处理**: - 将模型输出的概率分布转换为文字。 - 进行词性标注、命名实体识别等后处理。5. **用户接口**: - 提供语音输入和文本输出的界面。 - 支持命令控制、交互式问答等。6. **系统集成与测试**: - 将语音识别系统集成到其他应用中。 - 进行系统测试,确保性能稳定。对于使用者来说,基于人工智能的语音识别系统能够实现如下功能:- 语音转文字:将语音转换为文本,用于字幕、会议记录等。- 语音控制:通过语音命令控制设备或应用。- 交互式问答:与智能助手进行语音交互,获取信息或执行任务。任务包括:- 项目规划与管理:确定项目目标、进度和资源分配。- 技术选型:选择合适的语音识别框架和模型。- 成果评估:分析测试结果,优化系统性能。在技术方面,使用了如下的技术战:- 深度学习框架:如TensorFlow、PyTorch等。- 语音识别算法:如CMU Sphinx、Kaldi、Google的Wavenet等。- 自然语言处理技术:用于后处理和理解。项目成果可能包括:- 准确的语音识别率。- 流畅的用户体验。- 易于集成的API或SDK。难点可能包括:- 语音噪声和环境干扰。- 不同说话人的适应性。- 长短句的识别准确率。- 特定词汇或口音的识别。解决这些难点可能需要:- 使用更先进的模型和算法。- 增加训练数据,包括多样化的说话人和环境。- 应用语音增强技术,减少噪声干扰。- 进行细粒度的错误分析,针对性地优化系统性能。声明:本文仅代表作者观点,不代表本站立场。如果侵犯到您的合法权益,请联系我们删除侵权资源!如果遇到资源链接失效,请您通过评论或工单的方式通知管理员。未经允许,不得转载,本站所有资源文章禁止商业使用运营!

下载安装【程序员客栈】APP
实时对接需求、及时收发消息、丰富的开放项目需求、随时随地查看项目状态









评论