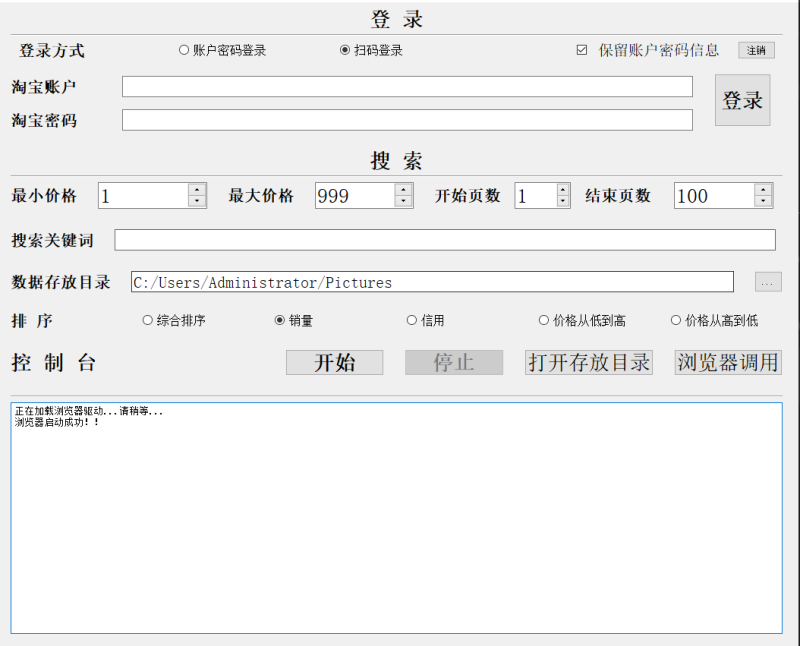
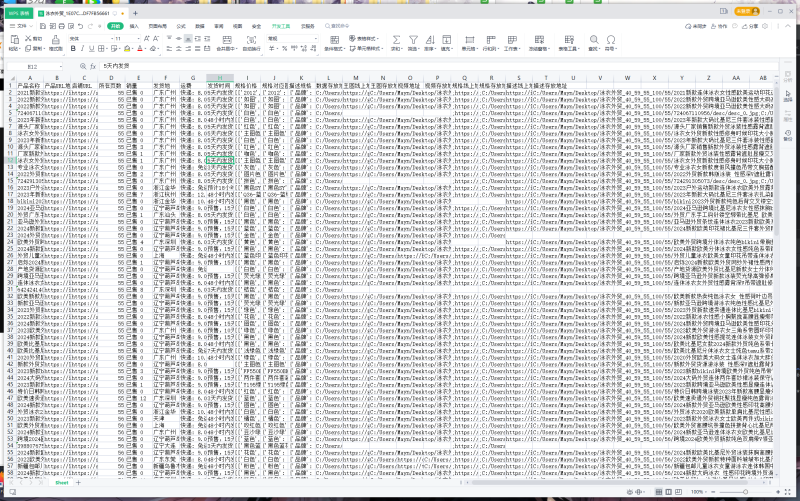
项目名称:某宝爬虫脚本开发一、功能模块及描述本项目旨在开发一款用于某宝平台的爬虫脚本,通过自动化方式实现登录、搜索、页面排序以及详情页数据获取等功能。具体功能模块如下:登录模块:扫码登录:利用selenium库模拟用户扫码登录流程,通过打开登录二维码图片,用户扫码后进行登录。验证码登录:针对需要输入验证码的情况,使用selenium识别验证码图片并提示用户输入,再自动填充到登录表单中。密码登录:通过selenium自动填写用户名和密码,并模拟点击登录按钮。搜索模块:利用selenium或request库发送搜索请求,获取搜索结果页面。提供搜索关键词输入接口,用户输入关键词后自动发起搜索。页面排序模块:通过selenium模拟用户点击不同的排序选项(如价格、销量、评价等),获取按指定排序后的页面数据。提供排序选项选择功能,用户可根据需求选择不同的排序方式。详情页数据获取模块:根据搜索结果中的商品链接,利用selenium或request库访问商品详情页。解析详情页数据,提取所需信息(如商品标题、价格、销量、评价等)。将提取的数据保存至Excel文件或进行其他处理。二、用到的技术pyqt5:用于构建图形用户界面(GUI),提供用户友好的操作界面,方便用户输入搜索关键词、选择排序方式等。selenium:自动化测试工具,用于模拟用户操作浏览器,实现登录、搜索、页面排序以及详情页数据获取等功能。openpyxl:用于读写Excel文件,将爬虫获取的详情页数据保存至Excel文件中,方便后续分析和处理。request:用于发送HTTP请求,获取网页内容,特别是在不需要模拟用户操作的情况下,直接获取搜索结果页面数据。re:正则表达式库,用于解析网页内容,提取所需信息。三、成果与展望通过本项目的开发,成功实现了某宝平台的自动化爬虫脚本,能够高效、准确地获取搜索结果和商品详情数据。该脚本不仅提高了数据获取的效率,还降低了人工操作的繁琐性。未来,可以考虑进一步优化脚本性能,提高爬取速度和稳定性;同时,也可以增加更多高级功能,如分布式爬取、数据清洗与整合等,以满足更多用户的需求。声明:本文仅代表作者观点,不代表本站立场。如果侵犯到您的合法权益,请联系我们删除侵权资源!如果遇到资源链接失效,请您通过评论或工单的方式通知管理员。未经允许,不得转载,本站所有资源文章禁止商业使用运营!

下载安装【程序员客栈】APP
实时对接需求、及时收发消息、丰富的开放项目需求、随时随地查看项目状态








评论