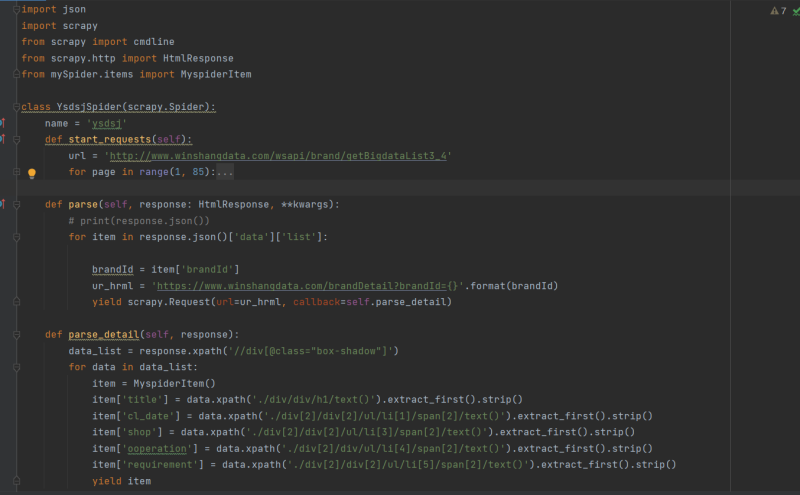
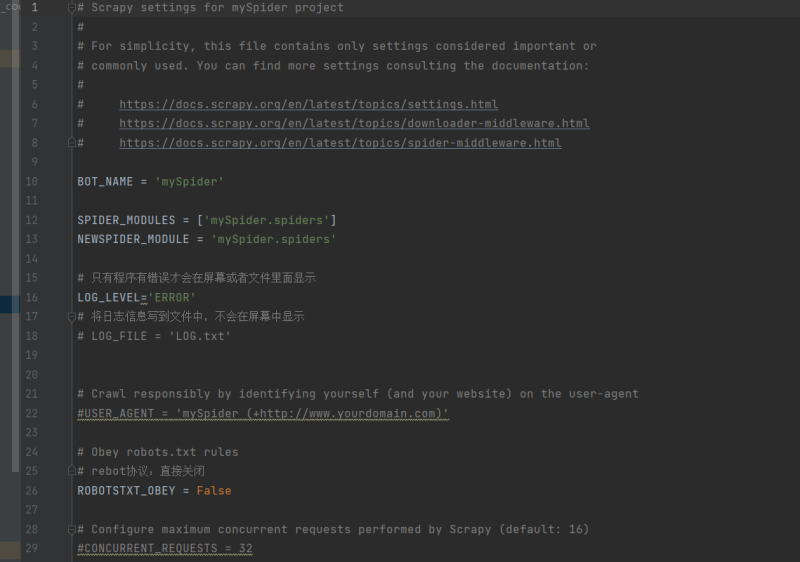
Scrapy是一个基于Python的开源网络爬虫框架,用于快速、高效地抓取网站信息和提取结构化数据。它提供了强大的工具和库,可以帮助用户轻松地创建和管理爬虫程序,从而实现网站数据的抓取、处理和存储。在Scrapy项目中,包括以下组件:Spiders(爬虫):定义了如何抓取特定网站的规则,包括起始URL、如何跟进链接、如何抓取页面内容等。Items(数据项):定义了需要抓取的数据结构,类似于模型,用于存储爬取到的数据。Pipelines(管道):负责处理爬取到的数据,如数据清洗、验证、存储等。Middleware(中间件):可以自定义扩展Scrapy的功能,例如添加代理、设置用户代理等。Settings(设置):用于配置爬虫的行为,如并发数、下载延迟、User-Agent等。声明:本文仅代表作者观点,不代表本站立场。如果侵犯到您的合法权益,请联系我们删除侵权资源!如果遇到资源链接失效,请您通过评论或工单的方式通知管理员。未经允许,不得转载,本站所有资源文章禁止商业使用运营!

下载安装【程序员客栈】APP
实时对接需求、及时收发消息、丰富的开放项目需求、随时随地查看项目状态












评论