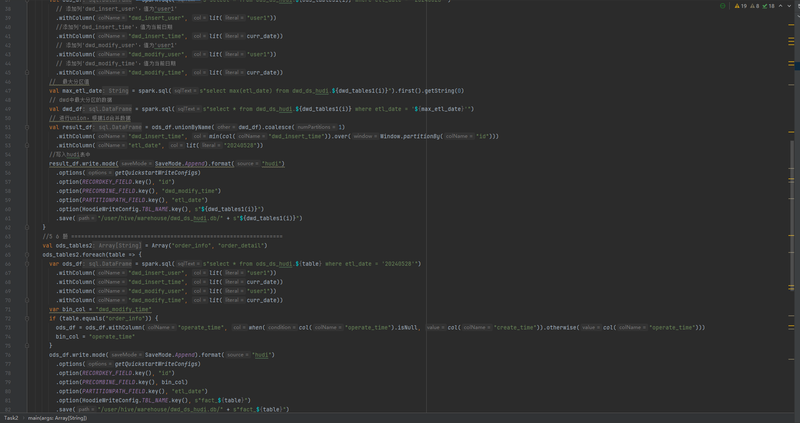
一、项目简介随着企业业务的不断扩展,数据量的快速增长使得数据的处理、存储和分析面临前所未有的挑战。为了更好地利用这些海量数据,企业数据入湖项目应运而生。本项目旨在构建一个高效、可靠、可扩展的数据入湖平台,通过Hudi数据湖技术以及其他大数据组件,实现数据的实时采集、清洗、转换和存储,为企业提供一站式的数据解决方案。二、项目模块与功能本项目主要划分为以下几个模块,每个模块都具有特定的功能,以满足企业的不同需求。数据采集模块:该模块负责从各种数据源(如数据库、API、文件等)中实时或批量采集数据,并将其传输到数据湖中。数据采集模块支持多种数据格式和数据源类型,确保数据的全面性和完整性。数据清洗模块:在数据进入数据湖之前,该模块负责对原始数据进行清洗和去重,消除数据中的噪声和错误,提高数据质量。数据清洗模块能够自动识别和修复缺失值、异常值、重复值等问题,确保数据的准确性和一致性。数据转换模块:清洗后的数据需要转换为适合存储和分析的格式。该模块支持多种数据转换方式,如数据压缩、加密、格式转换等,以满足不同的存储和分析需求。同时,该模块还支持数据的实时转换,确保数据的实时性和准确性。数据存储模块:利用Hudi数据湖技术,该模块负责将转换后的数据高效、可靠地存储到数据湖中。Hudi提供了增量更新、版本控制、快照查询等功能,使得数据的存储和查询更加高效和灵活。数据服务模块:该模块提供了一系列数据服务,如数据查询、数据分析、数据挖掘等,以满足企业不同部门的需求。通过数据服务模块,用户可以方便地获取所需数据,进行数据挖掘和分析,为企业的业务发展提供有力支持。对使用者来说,这些模块提供了以下功能:实时或批量地采集多源数据,实现数据的全面整合。自动化地清洗和去重数据,提高数据质量。灵活地进行数据转换,满足不同的存储和分析需求。高效、可靠地存储数据到Hudi数据湖中,支持增量更新和快照查询。提供丰富的数据服务,方便用户进行数据查询、分析和挖掘。三、我负责的任务与技术栈在项目中,我主要负责数据转换模块的开发和维护工作。为了高效地完成这一任务,我使用了以下技术栈:编程语言:Java,因其强大的面向对象编程能力和跨平台性,非常适合构建大数据处理系统。数据处理框架:Apache Flink,用于构建实时数据流处理应用,支持高吞吐量和低延迟的数据处理。数据转换工具:Apache NiFi,提供了一套丰富的数据转换组件和可视化的配置界面,方便我们快速构建数据转换流程。通过运用这些技术栈,我成功地实现了数据的高效转换和实时处理,确保了数据的准确性和实时性。四、项目成果通过本项目的实施,我们成功地构建了一个高效、可靠、可扩展的数据入湖平台。该平台利用Hudi数据湖技术和其他大数据组件,实现了数据的实时采集、清洗、转换和存储,为企业提供了一站式的数据解决方案。同时,我们还为用户提供了丰富的数据服务,方便用户进行数据查询、分析和挖掘。这些成果不仅提高了企业的数据处理能力,还为企业的业务发展提供了有力的支持。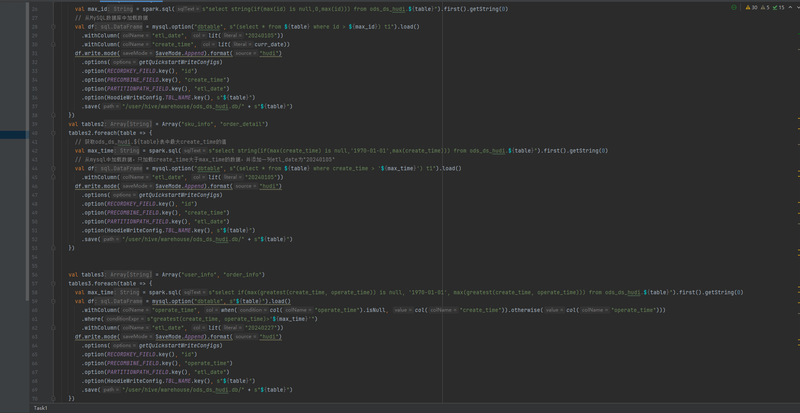
声明:本文仅代表作者观点,不代表本站立场。如果侵犯到您的合法权益,请联系我们删除侵权资源!如果遇到资源链接失效,请您通过评论或工单的方式通知管理员。未经允许,不得转载,本站所有资源文章禁止商业使用运营!

下载安装【程序员客栈】APP
实时对接需求、及时收发消息、丰富的开放项目需求、随时随地查看项目状态









评论