对c:\windows下的所有目录和文件进行一次遍历,分析文件目录有几层,完整的路径名和文件名需要多大的字符串空间等;系统目录中,有5万以上的子目录(文件夹)和将近20万个以上的文件存在。因此功能模块在设计中需要考虑足够的变量空间,如果采用递归程序,需要估计到系统是否能够支持足够层次的递归调用。文件的信息有许多,本次设计要求只需要考虑时间和字节数大小,其中时间是秒数,需要进行一些转换才能正确显示。遍历树型结构在数据结构的课程中有所了解,分为递归与非递归两种算法,在这次c:\windows扫描的过程中,由于文件和目录的数量过于庞大,选择递归遍历可能会造成堆栈溢出,所以应该采用非递归遍历的方法。设计关系数据库的表结构,有效地把扫描到的文件和子目录信息保存到数据库中,为后续更多的分析做准备;数据库中设计文件表和目录表,可以使用手工方式建立数据库的表等内容,然后将需要保存的文件/目录信息以SQL语句的方式进行体现,使用有效执行SQL语句的方式将文件/目录信息存入数据库中。内存中重构目录结构。后续进行文件的模拟操作和文件属性的统计,需要在内存或数据库中进行,则需要在内存中构建目录结构来保存必要的文件信息,这样对文件的属性进行修改操作时不会影响磁盘中的实际文件。根据遍历的结果构建孩子兄弟二叉树,便于后期对文件和目录的模拟操作。扫描指定的文件mystat.txt中的所有目录信息,若有些目录在本地电脑中不存在则跳过执行,统计处该目录下的所有文件数量,最早创建时间的文件和最晚创建时间的文件,以及总的文件的字节数。模拟文件操作,读取指定文件myfile.txt中的所有文件,A表示增加文件,提供文件名称和完整的路径以及大小和创建时间,D表示删除文件,M表示修改文件大小和时间。然后指定三条文件信息,比对操作之前和操作之后的文件信息的变化。之后再次扫描指定的文件mystat.txt中的所有目录信息,统计出来并与之前统计的目录信息进行比对,统计差异。模拟目录操作,读取指定文件mydir.txt中的所有文件,模拟目录操作中只有D删除目录,删除前需要指定一个即将删除的目录,再删除前后再查询目录是否仍然存在,并且统计子目录是否存在,若该目录和子目录都查询不到,则证明目录删除的结果成功。之后再次扫描指定的文件mystat.txt中的所有目录信息,统计出来并与之前统计的目录信息进行比对,统计差异。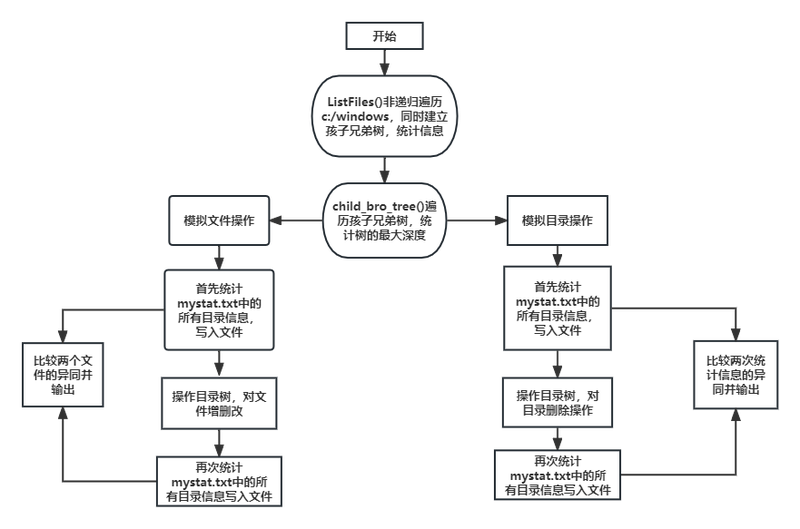
声明:本文仅代表作者观点,不代表本站立场。如果侵犯到您的合法权益,请联系我们删除侵权资源!如果遇到资源链接失效,请您通过评论或工单的方式通知管理员。未经允许,不得转载,本站所有资源文章禁止商业使用运营!

下载安装【程序员客栈】APP
实时对接需求、及时收发消息、丰富的开放项目需求、随时随地查看项目状态









评论