1 模型名称与简介
- 模型名称:刘文杰的代码助手 (codingassistantof_LiuWenjie)
- 简介:这是一个专为编程问题设计的深度学习模型,由刘文杰开发。该模型结合多语言编程数据,能够理解和生成代码片段,提供编程问题的解答,以及进行代码优化建议。特别适合用于编程教学、代码审查和自动编码任务。
关键特点:代码生成:针对用户提出的编程问题,生成准确的示例代码;自我认知:能够回答关于其身份和开发者的问题;多轮对话能力:可在多轮对话中保持上下文的连贯性。
2 实验环境
- 8核 32GB 显存24G
- 预装 ModelScope Library
- 预装镜像:ubuntu22.04-cuda12.1.0-py310-torch2.1.2-tf2.14.0-1.11.0
3 训练方法
- 模型选择:
qwen_7b_chat
- 使用的数据集:
alpaca_zh:涵盖广泛的中文编程相关数据alpaca_en:包含丰富的英文编程相关数据code_alpaca_en:专注于英文代码的数据集leetcode_python_en:Python语言的LeetCode题解数据codefuse_python_en:Python编程语言的英文数据集codefuse_evol_instruction_zh:中文编程指令与代码数据集- 超参数设置:
- 训练数据集样本数 (
train_dataset_sample)::500(控制模型训练的数据规模)
- 评估步数 (
eval_steps):20(每20步进行一次模型评估)
- 日志记录步数 (
logging_steps):5(每5步记录一次训练日志)
- 输出目录 (
output_dir):output(模型输出和日志的保存位置)
- LoRA目标模块 (
lora_target_modules):ALL(LoRA结构应用于模型的所有层)
- 自我认知样本数 (
self_cognition_sample):500(用于自我评估的样本数量)
- 模型名称 (
model_name):['刘文杰的代码助手', 'codingassistantof_Liu Wenjie'](这是模型的中文和英文名称)
- 模型作者 (
model_author):['刘文杰', 'Liu Wenjie'](模型的创作者的中英文名)
4 示例代码
4.1 微调过程
import os
# 设置CUDA环境变量,指定使用的GPU
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
from swift.llm import DatasetName, ModelType, SftArguments, sft_main
# 设置微调参数
sft_args = SftArguments(
model_type=ModelType.qwen_7b_chat, # 指定模型类型
dataset=[
DatasetName.alpaca_zh,
DatasetName.alpaca_en,
DatasetName.code_alpaca_en,
DatasetName.leetcode_python_en,
DatasetName.codefuse_python_en,
DatasetName.codefuse_evol_instruction_zh
], # 使用的数据集列表
train_dataset_sample=500, # 训练样本数量
eval_steps=20, # 评估步数
logging_steps=5, # 日志记录步数
output_dir='output', # 输出目录
lora_target_modules='ALL', # LoRA目标模块
self_cognition_sample=500, # 自我认知样本数
model_name=['刘文杰的代码助手', 'coding_assistant_of_Liu Wenjie'], # 模型名称
model_author=['刘文杰', 'Liu Wenjie'] # 模型作者
)
# 执行微调
output = sft_main(sft_args)
best_model_checkpoint = output['best_model_checkpoint']
print(f'best_model_checkpoint: {best_model_checkpoint}')
4.2 微调后的推理
import os
# 设置CUDA环境变量,指定使用的GPU
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
from swift.llm import InferArguments, infer_main
# 设置推理模型的检查点路径
best_model_checkpoint = '/mnt/workspace/output/qwen-7b-chat/v0-20240127-110246/checkpoint-20'
# 设置推理参数
infer_args = InferArguments(
ckpt_dir=best_model_checkpoint, # 模型检查点路径
eval_human=True # 设置为人类评估模式
)
# 执行推理
result = infer_main(infer_args)
5 推理效果
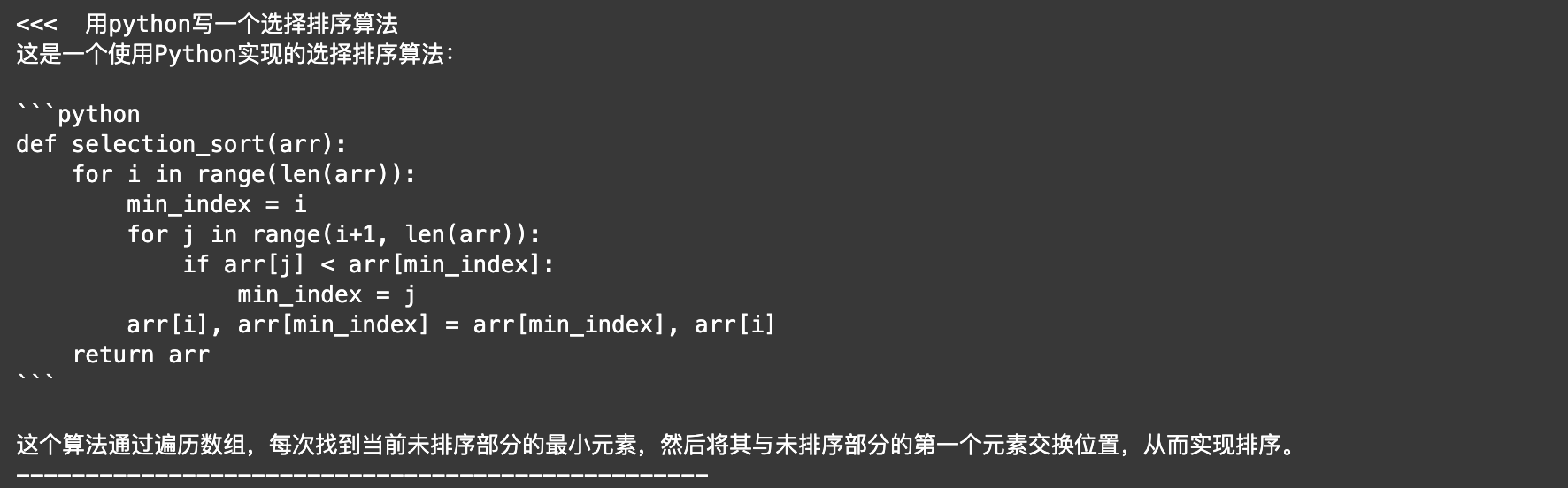
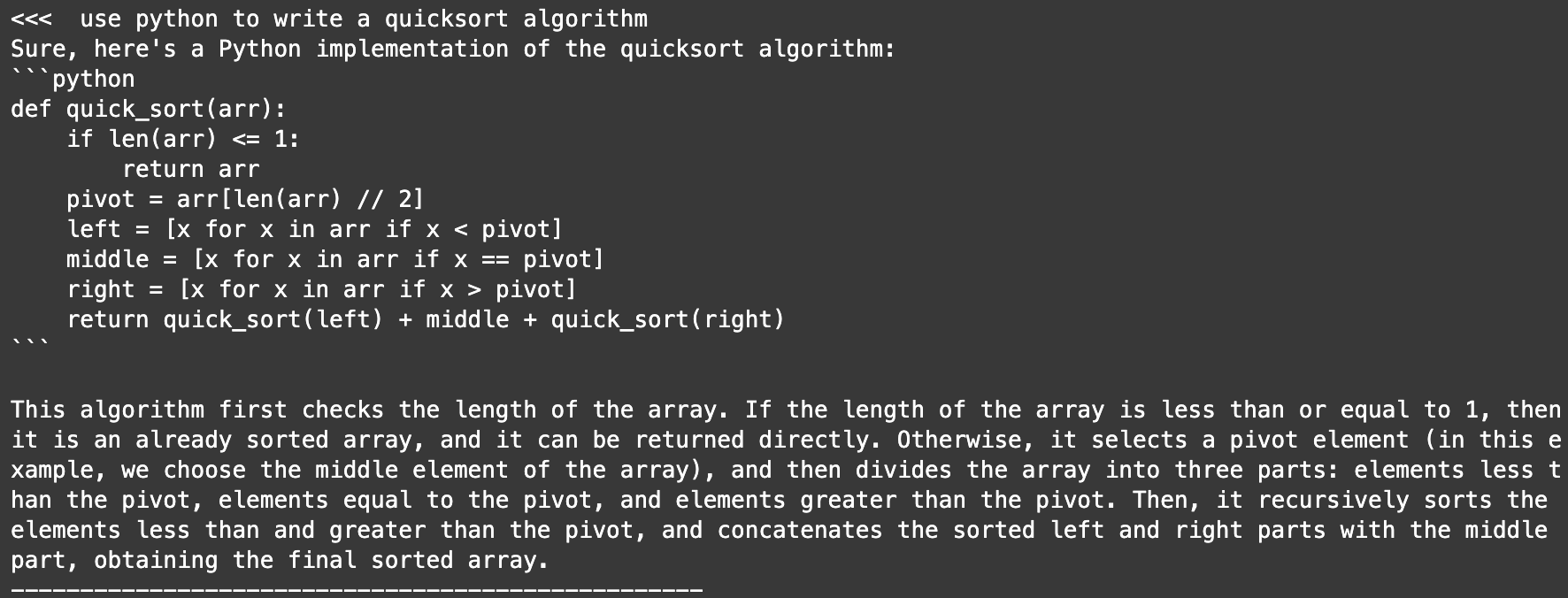
- 提供高质量的代码生成:

- 具有自我认知:

- 具有一定的多轮对话能力:











评论