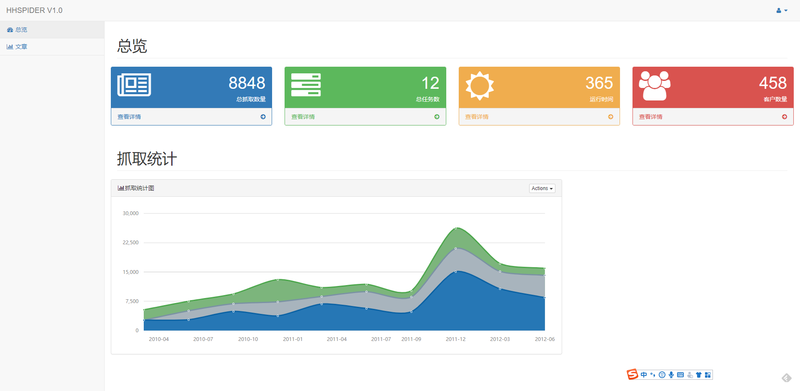
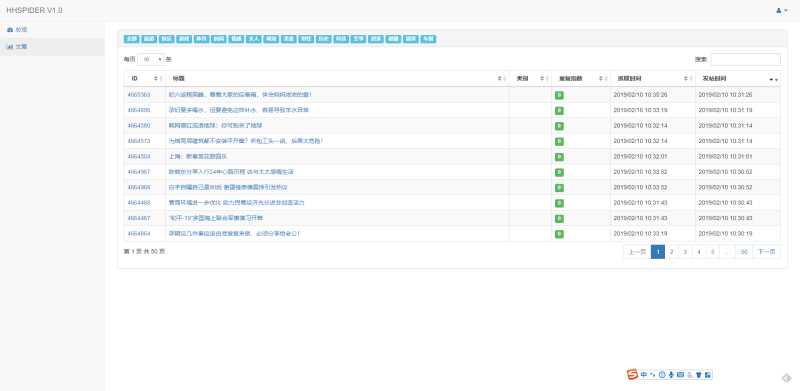
开始时间 :2018/11/05验收时间:2018/12/06使用技术:Python 3.6Django 2.1.3PILMySQL 5.7CeleryRedisBootstrap该项目是一个爬虫项目,客户需求是尽量快的抓取百度百家作者的前 20 篇文章,抓取文章的同时需要为文章中的图片去除水印,并保存在本地。该项目的开发阶段分三个,第一是文章的抓取,第二是过滤文章内容(去水印,入库),第三是文章的展示。爬虫部分使用 celery 的定时任务,调度 requests 通过百度百家的 ajax 接口获取文章列表,然后根据列表中的 id 拼装文章详情页面的 url, 最后完成文章详情抓取。抓取完成之后,为了抓取速度,我采用了把文章现行入库,然后等用户访问文章页面的时候再进行图片抓取和剪裁,图片的剪裁也是非常简单的,直接从底部开始去掉一部分就可以了。爬虫的前端展示部分使用 bootstrap 进行开发。最终爬虫的效率在客户 8C16G 的机子上跑满CPU 可以达到每小时 280 万条左右。声明:本文仅代表作者观点,不代表本站立场。如果侵犯到您的合法权益,请联系我们删除侵权资源!如果遇到资源链接失效,请您通过评论或工单的方式通知管理员。未经允许,不得转载,本站所有资源文章禁止商业使用运营!

下载安装【程序员客栈】APP
实时对接需求、及时收发消息、丰富的开放项目需求、随时随地查看项目状态








评论