

0
1
2
3
4
5
0
1
2
3
4
5

 ********
******** ********
********2017-11-27 -2021-01-06深圳华讯网络科技有限公司大数据开发
1. 负责大数据平台搭建和维护,组件集成和调优,以及数据采集、处理、存储、统计分析、报表开发、数据服务 2. 业务需求分析和讨论,数据仓库建设和优化、数据统计指标、用户画像标签、部分股票行情客户端指标计算,并开发实现 3. 对广告投放、运营、产品等部门提供数据分析支持 4.对接公司购买的大数据产品Convertlab DM-hub和火山引擎A/BTest平台等工作
2014-09-01 - 2017-06-16北京语言大学计算机科学与技术专科
项目名称: 湖仓一体化 开发架构: CDH+hadoop+hive+iceberg+flink+kafka+springboot+ES+mysql 项目描述:由于离线用户画像和指标统计,隔日才能看到报表数据,运营部门提出需求希望可以实时查看报表数据,实时通过技术手段调整运营策略和方式并触达用户,实现用户的快速增长和产品付费人数的增长,为公司带来业绩;同时营销部门也希望通过用户画像和数据分析,优化广告投放渠道,提高投入产出。以及数据分析人员需要即时OLAP分析,随时获取想要的统计分析数据。 系统实现:需求分析、标签和指标优化、前端埋点优化、数据采集优化、数据存储仓库优化、实时标签和指标统计开发并写入数据仓库、数据服务开发、前端报表开发、标签和指标测试、业务部门验收 项目职责:1、依据需求设计APP/PC/Web/H5/小程序,新增和删减埋点事件以及相关字段采集,埋点采集的数据测试和质量验证 2、业务系统用户、产品、订单等数据使用sqoop一次性全量拉取,canal解析mysql binlog实时增量写入iceberg/hive中;广告投放数据从广告平台定时获取导入; 3、参与用户画像签标和统计指标的需求优化,数据仓库优化,并使用hive+iceberg建立数据仓库解决业务数据缓慢变化维的问题,使用flink消费kafka后对数据进行ETL,保存在数仓DWD层中,flink整合iceberg实时聚合DWD层数据,按广告投放、运营、销售等主题保存到DWS层,使用flinksql标签开发和指标统计,新增活动、直播、股票热度、用户、订单等概况分钟级实时统计,标签保存在ES,指标保存mysql 4、使用spring开发数据提供接口服务 5、后续对flink 优化和维护
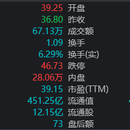
项目名称:股票F10 开发架构: kurbernate+docker+springboot+springcloud+kafka+flink+redis 项目描述:公司股票行情软件,在产品经理的推动下,不断迭代,股票F10和涨停基因等指标计算,也跟着技术架构升级,原c/c++实现的功能替换替换成java。而且需要满足在股票交易时间实时更新F10数据,市场热度和涨跌分布、涨停等计算,涨停基因离线计算即可。 系统实现:实时获取交易所行情数据快照,基于K8S部署Flink集群,Flink在股票交易时间段实时计算,保存再redis,数据微服务提供 项目职责:1、获取沪深交易所的实时行情数据并保存到kafka 2、flink实时(秒级)消费kafka行情数据,实时计算股票F10、涨跌分布、股票热度排行等指标,离线计算涨停基因、板块题材热度等指标数据,保存到redis 3、 spring开发数据服务
项目名称: 数字化运营 开发架构:CDH+hadoop+spark+hive+kafka+flume+springboot+impala+mysql 项目描述:随着公司业务发展,公司开发了股票行情APP,业务部门希望通过运营和活动促使用户对产品进行付费,所以运营部门需要及时了解业务实际情况,用户运营策略和产品功能调整,知晓用户处在用户生命周期的哪一个环节,然后针对性的运营,使其成为付费用户。 系统实现:需求分析、标签和指标设计、前端埋点、数据采集、数据存储仓库设计、离线标签和指标统计开发、数据服务开发、前端报表开发、标签和指标测试、业务部门验收 项目职责:1、依据需求确定APP/Web/H5/小程序/*聊天等数据采集方案。埋点事件以及相关字段采集,埋点采集的数据测试和质量验证 2、使用spring开发日志接受微服务,预处理过滤非完整json格式行为日志数据,依据日期时间过滤避免今天数据写到昨天,之后数据同步发送到kafka; 用户、产品、订单、支付等业务数据使用sqoop基于日期时间增量抽取到Hive中;flume配置kafka用户日志数据实时保存到Hive中 3、使用sparkstreaming实时(秒级)消费kafka用户行为数据ETL后保存到ES; 4、参与用户画像标签和统计指标的需求确定,基于星型模型构建三层ods、dwd、dws数仓,并使用hive建表,spark rdd离线T+1进行数据ETL,首先对用户标识进行idmapping关联不同数据源,清洗数据后使用parquet格式保存到数仓,用户日志数据,按年月日分区,按行为事件(启动APP、购买产品、浏览新闻等)分桶,之后sparksql开发运营指标统计、匹配规则类和统计类标签,预测类标签,用户标签保存在hive和ES和指标统计保存到mysql,impala提供OALP 5、使用spring开发数据提供接口服务




