

0
1
2
3
4
5
 ********
******** ********
********我是一名爬虫工程师,毕业于郑州工商学院
l 掌握:Python|Django|requests |JS|数据库的设计与实现Flask|scrapy|mongodb|selenium|xpath|正则表达式|Pandas|numpy|jupyter
l 了解:Linux|ajax|Html5+CSS|JS逆向|数据分析|app爬虫
l 了解charles以及fiddler抓包工具的使用
l 能够进行js逆向解析,了解scrapy框架数据流通方式,掌握多线程用以提高爬取速度
l 能够通过第三方平台进行处理验证码,ajax动态加载反爬,处理字体加密
l 掌握一系列基础性质反爬的应对措施:cookie检测,请求头检测,防盗链referer
l 能够进行数据分析,数据的处理,发现并处理数据异常,数据清洗,去重等
2023-07-12 -2025-05-21易安爬虫
负责爬取不同平台中不同航程的各自票价,然后进行数据分析比对,选出最优负责爬取不同平台中不同航程的各自票价,然后进行数据分析比对,选出最优
2019-09-05 - 2023-06-15郑州工商学院软件工程本科
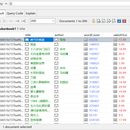
爬取了某瓣阅读全部小说的详细信息,书名作者售价等等,该页面的真实数据是由js动态渲染而成,此处采用抓包的方式寻找出真实数据的数据包,然后对其进行抓取,获得所有数据后用mongdb进行持久化存储,使用padnas对数据进行清洗并找出异常数据
使用夜神模拟器加上fiddler抓包工具,完成对*端app数据包的截取,然后分析出目标数据的具体情况,使用mongodb完成对爬取数据的持久化存储,最后使用jupyter工具加pandas完成对数据的清洗以及找出异常数据
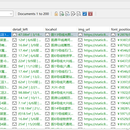
浏览整个网页的大致情况,发现房租并不是以真实数据呈现,而是以字体文件配合偏移值呈现出来,且不同页面的字体文件内容不同,此处使用第三方识别平台,识别出图片内容,然后解析出不同偏移值对应的具体数据,构造出映射字典进行替换,以完成字体加密的破解,之后使用多线程提升爬取速度,获得所有数据后用mongdb进行持久化存储,使用padnas对数据进行清洗并找出异常数据





