

0
1
2
3
4
5
0
1
2
3
4
5

 ********
******** ********
********本人电脑技术员出身,今年42岁,熟悉硬件、操作系统和基础网络技术,资深电脑维修技术员,擅长操作系统和软件安装调试、电脑硬件故障判断处理、宽带办公网络搭建和打印机复印机安装调试,台式机、笔记本、一体机、PC平板二合一的软硬件故障维修处理,本人特别热爱IT互联网行业,梦寐以求成为程序员和软件与网络工程师,现已自学完成C/C++语言、Python语言和高中数学课程,熟悉精通Python网络爬虫,已经独立完成27个Python爬虫项目,目前正在自学数据结构和JAVA语言,想在工作中边干边学,我的电脑维修技术也是以前自学的。本人的优点是富有刻苦钻研的科学精神,孜孜不倦,坚韧不拔,锲而不舍,不达目的誓不罢休,吃苦耐劳,任劳任怨。本人最近刚刚接触到了黑苹果技术,我在对苹果Mac系统从未接触,一无所知的情况下,通过不断的扒贴刷论坛熬夜钻研,五天时间成功的把苹果雪豹系统安装到十年前的普通双核组装机老电脑上。在学习Python语言的过程中,本人通过网上视频指导,自己独立钻研,成功的独立自主的完成了27个Python爬虫项目,精通熟悉爬虫程序框架。现在本人跪求一个兼职程序员工作,跪求程序员客栈上哪位程序员技术大咖或软件与网络工程师技术大咖带带我这个笨徒弟,我想先从程序员学徒做起,工资只要2000元就行,主要目的是想扎扎实实的学一门技术,掌握一门手艺,靠技术挣钱,实现心中的梦想和财富自由。再次诚挚的拜托并感谢各位程序员客栈上的行业资深老前辈们,跪求你们的知遇之恩,跪求大咖高人指点迷津引路。
本人在此向所有的行业资深老前辈们诚挚的叩拜,谢谢大家了。
2010-10-01 -2022-10-01汉中市诚信科技电脑维修工程师
本人电脑技术员出身,熟悉硬件、操作系统和基础网络技术,资深电脑维修技术员,擅长操作系统(Windows和苹果Mac OS)和软件安装调试、电脑硬件故障判断处理、宽带办公网络搭建和打印机复印机安装调试,台式机、笔记本、一体机、PC平板二合一的软硬件故障维修处理。
2001-09-01 - 2004-06-30陕西科技大学计算机科学与技术专科

项目分为四大模块,分别是xiaoesuoeswebfanyes.py主干文件模块、middlewares.py中间工具文件模块、settings.py反反爬设置文件模块、pipelines.py数据管道文件模块。 xiaoesuoeswebfanyes.py主干文件模块的功能:主要负责需要抓取的网站基础数据元素的提取方法构建,根据具体情况,可以使用Xpath和正则re两种方法,包括二级网址信息的抓取,可以构建独立的函数模块对二级网址网站内容基础数据元素进行提取,支持翻页爬取。 middlewares.py中间工具文件模块的功能:xiaoesuoeswebfanyes.py主干文件模块与pipelines.py数据管道文件模块之间互相传送调用数据的工具型功能模块,相当于数据管道的中间阀门。 settings.py反反爬设置文件模块的功能:网站反反爬设置的构建,包括用户代理USER_AGENT、Cookie、Referer。 pipelines.py数据管道文件模块的功能:需要抓取的网站基础数据元素所构成的items标签类对象汇总到pipelines.py数据管道文件模块,最终建立并保存为客户所需要的项目名称的JSON文件。
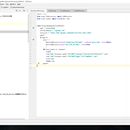
项目分为四大模块,分别是pictureshome.py主干文件模块、middlewares.py中间工具文件模块、settings.py反反爬设置文件模块、pipelines.py数据管道文件模块。 pictureshome.py主干文件模块的功能:主要负责需要抓取的网站基础数据元素的提取方法构建,根据具体情况,可以使用Xpath和正则re两种方法,包括二级网址信息的抓取,可以构建独立的函数模块对二级网址网站内容基础数据元素进行提取,支持翻页爬取。 middlewares.py中间工具文件模块的功能:pictureshome.py主干文件模块与pipelines.py数据管道文件模块之间互相传送调用数据的工具型功能模块,相当于数据管道的中间阀门。 settings.py反反爬设置文件模块的功能:网站反反爬设置的构建,包括用户代理USER_AGENT、Cookie、Referer。 pipelines.py数据管道文件模块的功能:需要抓取的网站基础数据元素所构成的items标签类对象汇总到pipelines.py数据管道文件模块,最终建立并保存为客户所需要的图片文件。
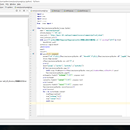
项目分为五大模块,分别是wanyiyunyinyuezjpl.py主干文件模块、items.py标签类文件模块、 middlewares.py中间工具文件模块、settings.py反反爬设置文件模块、pipelines.py数据管道文件模块。 wanyiyunyinyuezjpl.py主干文件模块的功能:主要负责需要抓取的网站基础数据元素的提取方法构建,根据具体情况,可以使用Xpath和正则re两种方法,包括二级网址信息的抓取,可以构建独立的函数模块对二级网址网站内容基础数据元素进行提取,支持翻页爬取,产生items标签类对象的具体数据元素。 items.py标签文件模块的功能:建立items标签类的类体,从wanyiyunyinyuezjpl.py主干文件模块接收items标签类对象的具体数据元素。 middlewares.py中间工具文件模块的功能:wanyiyunyinyuezjpl.py主干文件模块与items.py标签类文件模块和pipelines.py数据管道文件模块之间互相传送调用数据的工具型功能模块,相当于数据管道的中间阀门。 settings.py反反爬设置文件模块的功能:网站反反爬设置的构建,包括用户代理USER_AGENT、Cookie、Referer。 pipelines.py数据管道文件模块的功能:需要抓取的网站基础数据元素所构成的items标签类对象汇总到pipelines.py数据管道文件模块,最终建立并保存为客户所需要的项目名称的JSON文件。






