

0
1
2
3
4
5

 ********
******** ********
********多年使用 Python、VBA 程序语言,最多使用 numpy/pandas/os/webbrowser/wordcloud 等模块,擅长以工作任务为导向,完成算法设计;在职期间,从数据和报告业务角度出发,使用程序完成数据处理和报告输出工作,实现平台产品的自动化功能;此外,长期跟踪美妆健康、文化体育、高等教育、水务环保等行业相关互联网公开媒体信息,对行业分析具有一定敏感度;最后,本人具备很强的责任心,能够很好完成工作交付。
2017-03-23 -至今北京智慧星光信息技术有限公司数据分析工程师
公司在互联网数据领域具备一定优势,主要有数据平台、商情等10余种标准化产品。 在职期间:对外面向企业级客户,提供日周月度的数据报告服务以及突发事件分析等专项服务,其中涉及化妆品、保健品、文化体育、高等教育、智能手机、直销、金融等行业的上市公司以及知名企事业单位,主要工作包括但不限于品牌自身动态以及热点声量分析、行业竞对动态以及调性对比、事件追溯、危机监测等。 工作成就:推进日常工作自动化实现,推进线上平台自动化功能的实现,同时对数据平台的功能进行反馈,促进平台产品体验优化。
2012-09-01 - 2016-06-30中国传媒大学经济学(传媒经济管理)本科
2012年至2016年,本科就读于中国传媒大学传媒经济学,获得经济学学士学位。

为获取品牌活动在社交媒体上的互动类数据,使用 Python 编程语言爬取更新相关信息,自动化输出到本地 Excel 文件中。本作品作为媒体数据分析获取工作中会用到的小工具,实际为代码不超过100行的小脚本,其中引用了模块 requests_html ,展示了 Python 编程的基本功。
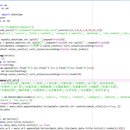
为实现媒体信息类数据的清洗整合与分析,调用了 Python 模块 os/xlwings/numpy/pandas 等,同时运用多种保留字结合经验规则,从而得到目标数据,极大方便了下一步的统计分析工作。

为生成热词词云,调用了 Python 模块 jieba/wordcloud 等,通过对自然语言进行分词、去除停用词和无意义词、统计词频、生成热词词云,更直观的获取海量数据中的热点信息。经不同时间的热词词云对比,还可获知热点信息的增减变换。





