

0
1
2
3
4
5
0
1
2
3
4
5

 ********
******** ********
********2014-05-01 -2019-10-01wps高级后端工程师
负责多个项目(文档分类,文档搜索等)后端开发、自动化测试、部署。实现一天自动发布70多个版本快速迭代,用户几乎0感知。有用中间件解决高并发的经验。
2011-10-01 - 2014-05-01西安理工大学计算机软件与理论硕士研究生
发表多篇ei检索的论文。培养了看最新论文复现论文算法的能力。
2006-09-01 - 2010-07-01河南财经政法大学计算机科学与技术本科
自己实现过数据结构书上几乎所有算法。得过国家励志奖学金。
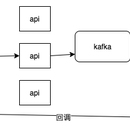
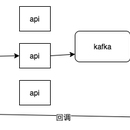
线上用户会产生大量文档,文档通常是docx,xlsx,pptx的格式,不能直接搜索。先把文档中的内容用tika抽取出来,再把内容放进elasticsearch建索引。
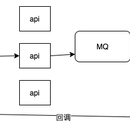
线上用户会产生大量文档,算法使用关键字和文档分类相结合的方法,自动判断文档中是否有非法内容。用LVS作负载均衡,golang服务器做api,rabbitmq当中间件,算法用python和pytorch实现。




