

0
1
2
3
4
5
0
1
2
3
4
5
 ********
******** ********
********2019-02-11 -2021-05-09武汉点宝科技后端工程师
10年三维信息系统开发经验, 5年带技术团队经验(15人以上),擅长后端技术架构设计和优化,擅长根据项目需求迅速做技术选型和组建所需团队开发产品,熟练掌握:python。
2016-05-09 - 2020-05-06大连民族大学信息与通信工程本科
本人就读大连民族大学信息与通信工程,通信专业
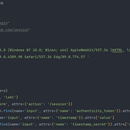
使用python爬虫技术,模拟浏览器登录GitHub网站;1.利用requests模块 构建一个会话Session, 2.访问GitHub登录网页 3.利用post提交username和pwd,登录成功; 3.session保存有登录后的cookies,之后可访问GitHub的其他页面进行操作
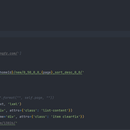
利用python Scrapy框架对抓取静态网页速度快的特点,来爬取信息量较大的书店书籍信息,从而加快了数据爬取的速度.1.获取书店总共书籍页数,2.分页爬取书籍链接,3.访问书籍链接爬取书籍信息 ,4.保存爬取的信息
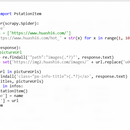
利用Python Scrapy框架爬取P站图片,1.获取热门首页2.解析网页,获取图片链接:获取图片标题作为字,和图片link3.判断下一页标片是否存在,如果存在,访问下一页4.递归解析5.重写item.py 定义构造数据格式:item['name'] = pictureLink6.重写管道文件,下载图片,保存图片




