

0
1
2
3
4
5
0
1
2
3
4
5
 ********
******** ********
********2022-11-09 -至今百度高级工程师
完成常见的视觉模型和LLM模型的推理加速、算法训练等等。完成推理框架相关模块的开发和相关项目的落地。熟练使用C++、Pytorch、TensorRT等。
2020-07-06 -2022-11-01顺丰科技后端开发
掌握后端开发常见技术栈,熟练使用C++、Golang、Java、Python等编程语言和相关编程工具。掌握Pytorch, Tensorflow, TensorRT等框架的使用和优化。同时掌握安卓app的开发和jni的使用。
2014-08-01 - 2018-06-01成都理工大学计算机科学与技术本科
英语四级CET4,计算机二级,熟悉Java,C++,做过多个项目
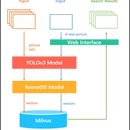
1. 使用视觉模型和目标检测yolov5完成物体检测和特征embedding的抽取 2. 使用向量数据库完成10亿级向量的快速搜索 3. 完成算法接口服务的开发并利用消息队列接耦

应用计算机视觉和大数据技术,为各行业提供算法服务。依托AI算法和云端推理平台,通过接口调用的形式使得个人、企业开发者可 高效使用AI能力,实现车牌识别、人脸识别、OCR、 二维码条码解析等AI能力。 1. 使用YoloV5进行目标检测,使用MTCNN算法完成人脸检测和关键点检测,使用多Batch方式提升吞吐量。 2. 使用MobileNet进行轻量级模型的训练, 在Android平台上封装为SDK, 使用 MNN在端侧进行推理,并利用模块化开发解耦各个算法的调用。 3. 使用PaddleOCR进行文本信息的提取。

驾驶员监控系统通过一个面向驾驶员的红外摄像头来实时监测头部、眼部、面部、手部 等细节,可以从眼睛闭合、眨眼、凝视方向、打哈欠和头部运动等检测驾驶员状态。通常通 过检测人脸眼睛和其他脸部特征以及行为,同时跟踪变化,实现驾驶员疲劳、分神、不规范 驾驶检测。从而及时提醒驾驶员达到安全驾驶的目的。 1. 使用OpenGL ES共享上下文双线程渲染技术。主渲染线程负责视频渲染和绘制, 在主线程之外通过共享EGLContext的方式开辟新的离屏渲染线程,将主渲染线程Camera生成 的纹理、VBO等资源共享,同时利用Fence机制完成GPU命令同步,实现数据流的实时获取。 2. 模型按需加载,降低内存占用。使用MNN框架完成YoloV5目标检测、分类等模型在CPU 的推理,利用CPU多线程加速。 3. 在移动设备上使用轻量级模型。部分网络使用MobileNet进行训练,利用Depthwise有效 减少模型的参数和运算量,降低推理时延。 4. 使用TensorflowLite在移动端推理





