

0
1
2
3
4
5
0
1
2
3
4
5
 ********
******** ********
********NLP拼写纠错任务(Spellcorrect) 滴滴实习
GAN+BERT+ngram
项目描述:主要任务就是负责滴滴搜索中的query纠错,我们使用了一种GAN对抗网络,其中生成模型主要是为了生成更加隐蔽的错误数据,然后还有一个判别器主要是为了提高模型对整个query的检测能力,纠错的主体架构是由一个GAN网络加上一个bert和ngram结构组成,我们在bert结尾加了一层线层用来判其中GAN和bert主要负责检测错误单词,ngram负责纠错,其中我们为了使得纠正之后的数据更加符合用户的意图,我们去掉了单个单词词频对结果的影响,然后我们还会从键盘位置对满足条件的值适当的提高权重,以达到提高模型的纠正准确率。目前正在打算发一篇关于纠错的论文正在筹备当中。
意图识别 滴滴实习
BERT+MLP+蒸馏+多任务模型
项目描述:这个是滴滴实习中的另外一个任务,给定一个真实用户的query文本,判断用户的搜索意图是店铺(shop)还是菜品(item)。目标语言有西班牙语、日语和葡语,通过构建数据集然后在自动标注数据机上训练(20 epochs),然后在人工标注的数据集上训练(10 epochs),保存验证集上表现最好的模型,接下来会对模型进行蒸馏,利用Teacher模型Bert的embedding权重初始化student模型的Word embedding ,模型分为单任务和多任务,为了提高匹配的概率,进行规则过滤,对过滤字典和输入的query做额外的数据过滤:去除所有不可见字(包括空格)和特殊字符,日语模型(单蒸馏模型)的F1为91.9%,西语模型(多任务蒸馏模型)F1为93.2%
智能NLP音频识别 毕业设计
CNN+RNN+LSTM+Tflite+HMM+vViterbi
项目描述:首先我们先训练一个模型,开始检测器由声学模型CNN组成,接着是一个双向LSTM,在向前和向后方向上都有128个单元,接着是一个完全连接的sigmoid层,有88个输出,用于表示88个钢琴键中每个键的开始概率。接着我们会用tp-spr和hmm文件去match最终的结果,其中算法用到了viterbi,动态规划,朴素贝叶斯,隐形马尔科夫等算法,其中走谱以及识谱模式,我们使用的两种方案,对于计算处理速度比较快的机型我们使用的是tflite,对于那些机型相对较老,CPU计算相对较慢的机型我们使用的onset算法,后来也尝试了silvet,aubio,BBC,qm等同类型机器学习的算法,但是效果相对较差。
文本分类
CNN+RNN+LSTM
项目描述:利用神经网络对一大段词汇进行分类,使其划分到的自己自己所属的类别中,首先对数据进行预处理,是一整段话划分为一个个词语,并对每个词语或单词的出现频率进行统计,第一次使用的是CNN算法,进行词表封装,数据集封装,类别封装,计算图的实现,在测试数据集上准确率是93.2%,最后使用RNN测试集准确率达到了91.2%。
图像分类器 CNN+Pytorch
项目描述:使用torchvision加载并且归一化CIFAR10的训练和测试数据集,然后由于torchvision 数据集的输出是范围在[0,1]之间的 PILImage,我们将他们转换成归一化范围为[-1,1]之间的张量 ensors,接着定义一个卷积神经网络 在这之前先从神经网络章节复制神经网络,并修改它为3通道 的图片(在此之前它被定义为1通道),定义一个损失函数和优化器,使用交叉熵Cross-Entropy 作损失函数,优化器使用SGD,最后将在数据迭代器上将数据循环传给网络和优化器。
智寻实时定位系统 互联网+创新创业大赛
JAVA API+Bmob后端云+手机传感器调用
项目描述:这是个互联网+项目,我们做的是一个基于GPS精细化定位系统研究与设计的项目,最终我们做成的一款叫做智寻的APP软件,能够实现电子围栏,老人摔倒监测报警,人口分布统计图,点聚合大数据显示,历史轨迹,常去地点查询,目标定位等一系列功能,我们这个软件会实时上传用户位置信息,从而可以对用户常去地点进行大数据分析,推测出家庭住址,工作地点,以及喜欢去哪家饭店吃饭等一系列的用户活动信息。
主要职责:作为这个项目的负责人,我带领项目组的其他成员通过不懈努力,终于完成了这个项目收获了互联网+创新创业大赛省级荣誉证书,在项目结题报告评委老师曾经邀请我们入驻我们学校的E创空间创新产业园孵化基地,但是由于某些原因就婉拒了老师的请求,在其中我主要负责云端数据库部署,和大数据统计分析,以及一些具体功能的实现。并且在项目期间,我们团队通过翻阅各种书籍,查阅资料,以及项目中获得的一些经验,写了一篇名为《深度学习的研究》的论文发表在中国科技博览上。
2021-04-01 -2021-12-01滴滴出行算法
NLP拼写纠错任务(Spellcorrect) 滴滴实习 GAN+BERT+ngram 项目描述:主要任务就是负责滴滴搜索中的query纠错,我们使用了一种GAN对抗网络,其中生成模型主要是为了生成更加隐蔽的错误数据,然后还有一个判别器主要是为了提高模型对整个query的检测能力,纠错的主体架构是由一个GAN网络加上一个bert和ngram结构组成,我们在bert结尾加了一层线层用来判其中GAN和bert主要负责检测错误单词,ngram负责纠错,其中我们为了使得纠正之后的数据更加符合用户的意图,我们去掉了单个单词词频对结果的影响,然后我们还会从键盘位置对满足条件的值适当的提高权重,以达到提高模型的纠正准确率。目前正在打算发一篇关于纠错的论文正在筹备当中。 意图识别 滴滴实习 BERT+MLP+蒸馏+多任务模型 项目描述:这个是滴滴实习中的另外一个任务,给定一个真实用户的query文本,判断用户的搜索意图是店铺(shop)还是菜品(item)。目标语言有西班牙语、日语和葡语,通过构
2019-09-01 - 华北电力大学软件工程硕士
在华北电力大学学习了三年,学习很多有用的知识。
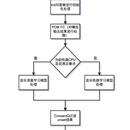
CNN+RNN+LSTM+Tflite+HMM+vViterbi 项目描述:首先我们先训练一个模型,开始检测器由声学模型CNN组成,接着是一个双向LSTM,在向前和向后方向上都有128个单元,接着是一个完全连接的sigmoid层,有88个输出,用于表示88个钢琴键中每个键的开始概率。接着我们会用tp-spr和hmm文件去match最终的结果,其中算法用到了viterbi,动态规划,朴素贝叶斯,隐形马尔科夫等算法,其中走谱以及识谱模式,我们使用的两种方案,对于计算处理速度比较快的机型我们使用的是tflite,对于那些机型相对较老,CPU计算相对较慢的机型我们使用的onset算法,后来也尝试了silvet,aubio,BBC,qm等同类型机器学习的算法,但是效果相对较差。

这个是滴滴实习中的另外一个任务,给定一个真实用户的query文本,判断用户的搜索意图是店铺(shop)还是菜品(item)。目标语言有西班牙语、日语和葡语,通过构建数据集然后在自动标注数据机上训练(20 epochs),然后在人工标注的数据集上训练(10 epochs),保存验证集上表现最好的模型,接下来会对模型进行蒸馏,利用Teacher模型Bert的embedding权重初始化student模型的Word embedding ,模型分为单任务和多任务,为了提高匹配的概率,进行规则过滤,对过滤字典和输入的query做额外的数据过滤:去除所有不可见字(包括空格)和特殊字符,日语模型(单蒸馏模型)的F1为91.9%,西语模型(多任务蒸馏模型)F1为93.2%

主要任务就是负责滴滴搜索中的query纠错,我们使用了一种GAN对抗网络,其中生成模型主要是为了生成更加隐蔽的错误数据,然后还有一个判别器主要是为了提高模型对整个query的检测能力,纠错的主体架构是由一个GAN网络加上一个bert和ngram结构组成,我们在bert结尾加了一层线层用来判其中GAN和bert主要负责检测错误单词,ngram负责纠错,其中我们为了使得纠正之后的数据更加符合用户的意图,我们去掉了单个单词词频对结果的影响,然后我们还会从键盘位置对满足条件的值适当的提高权重,以达到提高模型的纠正准确率。目前正在打算发一篇关于纠错的论文正在筹备当中。




