

0
1
2
3
4
5
 ********
******** ********
********就读于东莞职业技术学院,物流管理专业,本人沉着冷静、条理清楚、立场坚定、顽强向上,乐于助人和关心他人、适应能力和幽默感、乐观和友爱,对python语言有一点了解,主要方向为python爬虫,数据可视化,在广州公司做过几个月,做过新浪微博爬虫, 天猫商城,京东商城,淘宝商城等电商平台,以及对抖音,快手等平台的爬取,然后我也紧跟时代发展的浪潮,在学习java,c++等语言,也对前端有一定的认识
2020-06-15 -2020-10-16广州脑动网络科技有限公司python爬虫工程师
主要根据公司需求,对各大平台数据的爬取,利用requests,scrapy框架实现爬取,用bs4,xpath,正则对想要的节点爬取,for循环设置翻页,爬取的数据可存放本地,存入excel,也可以存入数据库
2020-10-18 - 2023-06-15东莞职业技术学院物流管理专科
于2020年10月18日入读东莞职业技术学院,将于2023年6月15日毕业
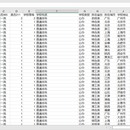
爬取全国各地区的大学,可进行数据可视化,也可根据各大学的分数以及各大学热度进行排名,数据可视化可用柱形图统计全国各省的大学数量,也可用折线图统计各省学生上大学的比例

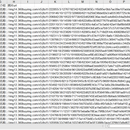
1. 采用 requests实现爬取。 2. 用 xpath 提取想要的节点,以列表形式存储。 3. 根据分析出下一页的链接规则,运用re去获取数字,添加到url中继续爬取,下一页面直到获取不到。 4. 把爬取的内容存入本地磁盘,excel,也可存入数据库。




