

0
1
2
3
4
5

 ********
******** ********
********我是程序员客栈的DM1209,一名python爬虫程序员; 我毕业于成都东软学院 负责过猫眼经典100,链家租房信息爬取与存储,豆瓣top250的开发; 熟练使用requests,css,xpath选择器,掌握scrapy爬虫框架,熟悉编译前端技术,熟悉反爬策略; 如果我能帮上您的忙,请点击“立即预约”或“发布需求”!
2022-08-13 -至今无无
没有工作经历,目前主要学习研究爬虫技术,希望在其中能够学到很多东西,还能学到更多的技术
2018-09-01 - 成都东软学院网络空间安全本科
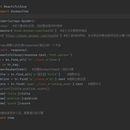
项目使用scrapy爬虫框架,BeautifulSoup模块,yield item对象推送给pipeline,创建函数pares,它是Scrapy中默认处理response(响应)的一个方法,然后提取想要的数据,将数据封装交给引擎,然后在pipeline文件中将数据保存至excel文件中
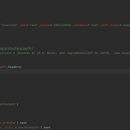
引入requess模块,mysql.connector模块以及bs4中BeautifulSoup模块,创建一个类,用一个对象接收连接MySQL数据库,创建三个函数,分别为请求数据,解析数据,保存数据,最后创建执行模块执行爬虫。
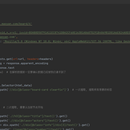
利用requests模块请求网址,添加请求头headers预防反爬,获取数据和确认数据后,再利用parsel模块解析数据,利用xpath选择器提取网站上想要获取的数据,最后序列化操作,存储到csv文件中。





