

0
1
2
3
4
5
0
1
2
3
4
5

 ********
******** ********
********我是程序员客栈的啊诚,一名视觉软件工程师; 我毕业于阳光学院,担任过诺博视有限公司的软件工程师 负责过物体识别,字符识别,自动化设别显示的***、chatgpt二次开发产品制作; 熟练使用python,C#,C++,pytorch,tensorflow,QT,opencv; 如果我能帮上您的忙,请点击“立即预约”或“发布需求”!
2024-05-27 -至今厦门天马显示科技有限公司算法工程师
公司主要生产手机、车载显示屏。我的主要工作是使用深度学习对镜片生产过程中进行缺陷检测,判断镜片是否异常;对标识进行字符识别。
2022-06-06 -2024-01-12诺博视科技有限公司软件工程师
从事视觉开发和人工智能领域:为自动化设备设计数据传输和按键功能、界面显示;使用youlov5进行物体检测;使用MaskTextSpotte3进行字体识别等。
2015-09-01 - 2019-06-09阳光学院电子信息工程本科已认证
基于*小程序的在线商城点单系统: 前言:能够支持线上下单,既方便客户也方便自己。系统采用C#语言作为后端实现与小程序的交互 项目介绍 1.小程序主要有首页、商品详情、购物车、个人中心等模块。 2.管理端主要有人员管理、商品管理、订单管理等模块。 相关技术 1.html+css+js:*小程序界面。 2.NetCore框架+C#程序语言:小程序及后台管理系统API的实现。 3.Layui前端框架:web后台管理界面样式及数据渲染框架。 4.SqlServer数据库:数据支持。
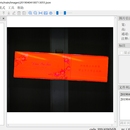
SAM标注+yolov8-seg实例分割的实时检测步骤: 1、图片采集制作数据集,用SAM进行标注,标注完后将保存的json文件组织形式为isat,转为yolo格式,并划分数据集 2、yolov8模型训练。修改数据集的配置文件coco128-seg.yaml和模型的配置文件yolov8-seg.yaml 3、导出onnx 4、实时检测 网络优化: 1、使用模型剪枝技术,去除不必要的层和参数,以减小模型大小和提高速度。 2、对模型进行量化,将浮点数权重转换为整数权重,可以显著提高推理速度。 数据增强: 3、使用更多的数据增强策略,例如随机缩放、旋转、亮度调整等,以增加模型对不同角度和光照条件下的籽粒的识别能力。 特征融合: 考虑使用注意力机制或特征金字塔网络(Feature Pyramid Network,FPN)等技术,以融合不同层级的特征图,以提高检测性能。 增强训练数据: 通过合成数据或从互联网上获取更多多样性的籽粒图像来增强训练数据,以提高模型的泛化性能。 超分辨率: 将图像进行超分辨率处理,然后再进行检测,以增加微小颗粒的可见性。

文本检测: CTPN:核心思想是将图片按宽度为16像素分成很多个小格,检测每一个小格中是否包含文本,同时预测文本的高度和宽度。最后将多个检测结果融合,形成最终的文本框。CTPN缺点:对于倾斜和弯曲的文本检测效果很差,这个是因为模型自身的原理决定,很难通过训练解决。 CRAFT:可以识别任意角度的文本,而且可以给出图片中每一个像素为文本的置信分。在深度学习的OCR文本检测中,有一个很大的痛点就是在图片里有比较大的文本和比较小的文本的时候,小文本容易被漏检,这是因为采用了类似region proposal原理的算法(比如CTPN),很难通过调参或者数据集解决。而Craft由于是像素级别的预测,在这方面有天然的优势,不会漏检图片中的小文本。 Seglink:在CTPN基础上进行改进,利用开源项目测试了一些比较模糊的图片,发现效果不是很好,暂时没有深入研究,从论文的结果来看,在复杂场景下的识别效果要好于CTPN。 EAST:在Seglink基础上的改进算法,在识别倾斜和弯曲文本的效果上比较好 文本识别: CNN+RNN+CTC:其中CNN用于提取图像特征,RNN在CNN提取特征的基础上,通过双向LSTM提取相邻下像素之间的特征,最后CTC用于计算损失函数。 CNN+Seq2Seq+Attention:引入了attention机制,通过开源项目的测试,效果相当好 keras开源库:实现了文字检测和文字识别的整合,其中文字检测用的是CRAFT,文字识别用的是CRNN





