

0
1
2
3
4
5

 ********
******** ********
********我是程序员客栈的夏日的海,一名技术。
我毕业于国开大学,担任过博爝建筑工程有限公司的技术。
负责网络一手数据抽取
熟练使用request,正则,selenium,xpath,scrapy等。
如果能帮上你的忙,请点击“立即预约” 或 “发布需求”!
2018-02-01 -2022-10-22上海博爝建筑工程有限公司技术员
公司主要建筑装修装饰工程,消防工程,桥梁工程,公路工程,地基与基础工程,建筑材料销售这一块,我一般负责抽取网上一线数据拱公司研究
2020-05-01 - 2022-07-01国家开放大学机械制造及其自动化专科
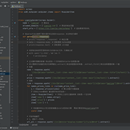
这个项目参考scrapy企业级开源爬虫框架,目标为链家租房,由于scrapy下载速度过快,有很少的网站对这方面不做限制。 该项目创建完成后就有一个总项目目录和几个分页面,主要代码是在spiders文件下的链家.py写入,主要是settings里面的相关配置一定要开启。
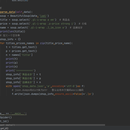
使用爬虫抽取京东的商品信息,首先导入应用库。由于我是使用的selenium库,模仿人工点击不会轻易造成封IP等再加上time.sleep进行休眠,所带的影响会更加的小,让代码也能在甲方的电脑上也能正常运行如飞。其次再根据xpath来抽取甲方想要的信息也相对的方便,可以跳过任意层级。最后将网页里的信息保存到数据库,方便导出。

1.View模块 : 负责接收HttpRequest(客户端)对象,对客户端发送过来的url进行正则匹配,让相应的函数进行信息处理 (1.Template模板 : 模板实现了逻辑处理view和现实内容的template的分离,一个试图可以调用任意模板,一个模板可供多个view使用。js、html、css、img等,模板语言 (2.URL模块 : Django的路由系统,建与views里面处理数据的函数与请求的url建立映射关系。使请求到来之后,根据urls.py里的关系条目,去查找到与请求对应的处理方法,从而返回给客户端http页面数据..... (3.数据库 ...... 2.我负责编译后端的这块整体 3.在编译的过程中,出现pycharm源码与现译代码向冲报错,这种情况简单的修改源代码,实若不行就问问朋友有没有遇到相同的问题并请教,探讨。




