

0
1
2
3
4
5
0
1
2
3
4
5
 ********
******** ********
********新加坡国立大学计算机科学与数据科学博士生在读
浙江大学计算机科学与技术学术硕士
西安电子科技大学计算机科学与技术学士
曾获中国国家国家知识产权局授权发明专利(爬虫)相关专利两项(第一作者,且合作者为浙江大学校长吴朝晖院士(十九届中央候补委员)),美国专利局发表专利一项(爬虫相关).
参与国家高分辨率对地观测系统重大专项,任开发组长
做过20+项目,包括前端,后台,门户网站以及实用python pip包等
发表国际论文6篇,引用量超200,研究方向为OpenCL/CUDA并行加速,机器学习模型,服务计算等.
曾获国家奖学金,西电特奖,ACM一等奖,互联网+创新创业大赛二等奖,CCF-CCSP优秀选手奖等20+奖项
GitHub主页:https://github.com/NaiboWang
个人主页:http://naibo.wang
2022-10-03 -至今新加坡国立大学服务器管理员
兼职服务器管理员,对新加坡国立大学数据科学学院的GPU服务器进行管理和维护。 •监控服务器的使用情况,识别占用GPU内存的未使用进程,联系用户清除未使用进程,定期手动清除服务器中未使用进程,以及所有其他操作,以保持服务器的良好状态。 •设计了一个非常有用的工具,为所有用户检查GPU的状态和谁正在使用它的电子邮件地址,只需“ids”命令;自动检查僵尸进程并杀死它们;让用户发送匿名邮件到过度使用gpu的用户等等。
2021-12-01 -2021-12-02新加坡国立大学全栈开发工程师
担任全职全栈软件工程师,构建加密货币交易市场/平台。 •负责使用多种语言和框架构建系统的完整前端和部分后端。 •设计数据库结构,参与需求设计,将平台部署在安全稳定的服务器上。
2020-09-30 -2020-12-31新加坡国立大学助研
负责文献综述、体系建设、评价和实施。 •撰写了关于联邦学习系统的论文,可实现机器学习模型的协作训练在隐私限制下的不同组织之间。
2017-09-16 -2020-06-30浙江大学高级爬虫工程师
设计爬虫框架,可任意爬取任何网页的任意数据且无需代码,所写框架已获得中国国家知识产权局授权发明专利两项以及美国政府专利1项,均为第一发明人且合作者为浙江大学校长吴朝晖院士
2016-09-01 -2017-06-30西安电子科技大学软件开发工程师
曾任西安电子科技大学计算机学院兼职软件工程师 • 为西安电子科技大学的学生开发了一个信息中心“三思”,让他们能够访问学术信息。 该网站提供的信息包括GPA、排名、成绩证明、官方成绩单预约、入学声明等。 • 协助教授对学生的毕业设计进行在线评分,并协助教师通过在网站上发布公告来招收优秀学生。 • 单独负责后端系统的所有开发、前端设计、UI 设计和测试。 • 其他示范项目包括螃蟹验证码服务系统、留学生信息管理系统、高分辨率地对地观测服务网格系统(浙大)等。
2020-08-03 - 新加坡国立大学计算机与数据科学博士
计算机与数据科学博士生在读,研究机器学习模型与数据分析
2017-09-01 - 2020-06-30浙江大学计算机科学与技术硕士
计算机科学与技术学术硕士,研究方向为服务计算和数据处理,发表两项国内专利一项国际专利
2013-08-24 - 2017-06-30西安电子科技大学计算机科学与技术本科
计算机科学与技术专业,获得国家奖学金,特奖,ACM一等奖等奖项,专业成绩第一名
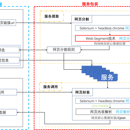
Service Wrapper是一种基于网页分割算法的网页数据提取封装系统。该系统仅需用户少量点击即可得到网页中的核心元数据的位置描述信息,将HTML文档转换为结构化数据,封装成服务,并提供可直接调用的RESTFul API接口。 Service Wrapper通过服务提取和服务调用两个模块来实现系统的后台功能,并提供了一系列简单的前端操作界面以辅助用户完整地实现整个操作流程。服务提取模块面向服务包装者,该模块利用爬虫工具和网页分割技术得到网页核心数据位置,并根据数据在网页中的结构生成网页分割规则, 存储在数据库中。服务调用模块面向服务调用者,该模块为每个服务提供 RESTFul API 的描述信息和调用方法,服务调用者正确调用后,该模块返回结构化的数据。 同时,该系统提供了包含服务提取、服务调用和服务信息展示的一系列前端操作页面,供用户可以方便地使用之。
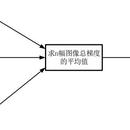
本工作完成了基于OpenCL的卷积神经网络的并行设计,验证了所设计算法在异构并行平台上的可行性和正确性。 在分析手写数字识别的卷积神经网络基本结构的基础上,总结了基于OpenCL的卷积神经网络训练的优化方法,提出了单卷积过程并行、多卷积任务并行、多卷积数据 并行和批处理等基于openCL的并行优化程序,并完成优化程序编程。 CNN算法的训练、测试过程和仿真均在Intel CPU、AMD GPU和NVIDIA GPU平台上实现。 测试结果表明,在相同训练准确率的情况下,本文提出的并行优化方案比串行执行方法快约375倍。

全部自己开发,包括前端后台数据库服务器配置等 负责学生信息管理,成绩单查询,新闻博士,保研信息查询,自动生成问卷等 可预约成绩单,查看新闻,填写问卷等等信息






