0
1
2
3
4
5
0
1
2
3
4
5
 ********
******** ********
********熟练使用Python语言进行编程。熟练掌握爬虫所需的库,如requests,xml,selenium,re等。熟练掌握Scrapy爬虫框架。熟悉前端知识,如html,css,js。曾经抓取过网易云音乐,豆瓣,boss直聘,以及各大新闻网站。有着丰富的爬虫与反反爬虫经验。熟悉MySQL与MongoDB数据库,可以实现Python与其对接。
2020-08-12 -2023-08-03杭州清莲数据爬虫工程师
python爬虫,在公司担任爬虫工程师,在工作的三年内,爬取过起点,微博,淘宝,苏宁,京东,每日优鲜,得物,饿了么等网站,工作内容爬取数据,去重,清洗,入库
2017-09-01 - 2021-08-06江西师范大学软件工程本科
主修课程:线性代数、高等数学、概率论、算法分析与设计、SQL数据库、云计算与大数据等课程。
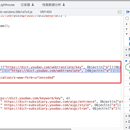
1. 通过抓包、拿到JS的请求入口、构建数据的目标函数实现JS逆向。 2. 再通过定位到解密数据函数,利用python进行解密数据。拿到sign和相关的值。 3. 最后返回相应的翻译数据。
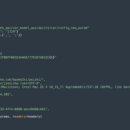
1. 利用python的requests模块、hashlib、execjs技术爬取易车网的各种车型信息。比如车价、型号、相关的各种配置。 2. 重构JS代码进行爬取