

前端
0
1
2
3
4
5

 ********
******** ********
********我是程序客栈的啊克,一名前端开发程序员,毕业于西安电子科技大学。先后在
广州多益网络担任客户端程序, 引擎: Cocoad2d和多益自研的2D引擎 语言: Python
上海完美世界担任客户端程序, 引擎: Unity 语言: C#
广州漫灵软件担任客户端主程 引擎: cocos2d和Unity 语言: Lua + C#
上海紫龙游戏担任引擎开发程序 引擎: Unity SRP 语言: C#
我在游戏开发行业有12年的经验,主要负责gameplay的开发和相关的性能优化。此外,我参与开发过Unity Scriptable Rendering Pipeline,具备一定的渲染方向上的能力,可以定制和优化渲染管线相关的功能。
作为一名前团队负责人,我了解高质量代码风格的重要性。良好的命名约定、适当的代码注释和标准化的代码布局可以极大地提高代码可读性。熟练掌握面向对象编程和MVC。我致力于产生高质量的代码,并与团队成员有效地合作。
如果能帮上您的忙,请点击“立即预约”或者“发布需求”
2021-10-15 -2023-01-28上海紫灏信息技术有限公司引擎开发工程师
在技术中台负责RenderGraph的重构和一些新的渲染feature的开发。包含Depth of Field,Raytraincg ScreenSpaceReflection等
2014-02-10 -2021-11-15广州漫灵软件有限公司客户端主程
在该公司我主要单位客户端主程,负责Coco2D和Unity的游戏。期间做过塔防,类《我叫MT》的卡牌,类《dota传奇》的卡牌,类《剑与家园》的卡牌以及一款能盈利的三国SLG。早期以coco2d为主,从2017年开始逐步进入Unity开发。能独立搭建Unity开发框架,指定一套完成的开发流程,并实现开发高质量的千人战争的玩法。
2011-03-09 -2014-02-10广州多益网络有限公司客户端程序
我刚毕业就去了广州多益,后来去了在上海完美世界待了几个月又和朋友去创业。期间主要负责一些UI部分的开发,后面转入到gameplay的开发。
2007-09-16 - 2011-07-01西安电子科技大学长安学院计算机科学与技术本科
基于RayTracing的Screen Space Reflection是我独立完成的一个渲染feature。 Screen Space Reflection是一个在传统Grapic管线下难以实现的效果,因为传统管线并不能记录到屏幕外和没有显示的像素的数据,所以当你使用RayMatching技术反射到一些你看不到的像素时,就不能正常渲染。或者镜像再渲染一次,这样的渲染开销基本就翻倍了,除非是特定场景的特殊优化,不然没人这样做。但是在RayTracing下,这些都能很好的被解决。但是RayTracing本身的问题是,一个需要DX12,一个需要较大的显存以及本身消耗巨大。所以在过去,大家都是用RayTracing做烘培,但是现在已经出现了RayTracing的Runtime算法,这样使RayTracing可以在PC游戏上得到很好的应用。 问题及解决方案: 1 代码兼容的问题,Raytracing管线虽然提供了整体的渲染数据,但是渲染部分仍然需要复用当前管线的代码。其中会有很多信息是传统管线中存在,但是Raytracing管线中没有的,比如坐标系的变化矩阵。还有一些采样函数的使用不同以及一些语法不同。这部分只能靠良好的代码管理能力去解决,最后通过宏去完成了兼容。 2 RayTracing消耗非常巨大,所以需要一个非常好的算法去优化。目前主流的算法都是用重要性采样和MotionVector采样历史帧信息的方式去得到当前帧信息得方式,在将当前有噪点的图片通过高斯模糊去噪。重要性采样解决了在较少的射线下,可以得到一个噪点较少的图(目前我们一个像素只会有一条到3条的射线)。但是在几条射线下几乎是不可能完成一个近似的球面积分(蒙特卡洛积分)的运算的,高精度下烘培,我们都需要几千条射线才能完成一个像素的球面积分计算,所以这里我们需要使用历史帧的信息(这种算法来自与TAA)。我们通过记录MotionVector来找到当前像素在上一帧中信息(如果找不到则默认为当前色),这样就可以累加每帧的射线信息。在60帧的情况下,几秒后我们一个像素就会累加几百条射线。在通过重要性采样和模糊算法,我们可以得到一个相对不错的效果。唯一的缺陷是,在相机发生快速变化时,粗糙度交高的地方,也就是漫反射越明显的地方会有噪点。这个目前只能通过调高每帧的射线数量去解决,但是射线数量是将性能N倍放大的参数,所以RayTracing目前最好是20系列以上的N卡。 3 处理采样的mip问题,RayTracing中mip层级的计算是要自己完成的,这点跟传统管线差异很大。该算法来自 RayTracing Gems,根据射线距离相机的距离,计算采样的mipLevel。最终我实际测试的效果非常好,几乎跟传统管线一致,唯一的缺陷是编码上我们需要所有修改曾经的Simapler函数,试图想用编程技巧去解决这个问题,但是在所有可能性被否定之后,目前还是挨个去替换了。 (该功能已经是完整能上线的版本,但是因为版权问题我不能上传任何相关的截图,所以只能传一份测试阶段的图。)
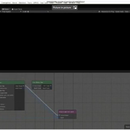
这是一个由Unity RenderGraph的二次开发,将渲染管线可视化后可快速的自定义自己的渲染管线。我在这个项目中担任的是处理RenderGraph的解析和相关的运行,日志以及RenderTexture的管理。以下链接是官方公布技术分享https://developer.unity.cn/projects/612741adedbc2a484ade66de RenderGraph的简介: RenderGraph是一个可视化的工具,我们可以创建相应自定义的节点和连线,所以我们将Scripatble Render Pipeline的各个feature映射到节点(比如Draw Opaque,Draw Transparency,TAA, DOF等),将各个feature的依赖关系用连线表示,这样我们得到一个有向的拓扑结构,而最终我们需要从这个拓扑结构中,在满足现有依赖关系的情况下得到一个节点队列,这个队列将是运行时各个feature的执行队列。因为渲染管线的一个特性,就是只有一个出口。所以在解析阶段,我从出口节点出发逆向遍历,这样不但可以剔除掉无用的节点,还可能得到一个满足依赖关系的执行队列。 RenderGraph的问题: 以上得到的这个执行队列并不是最优的,因为拓扑是网状的,所以这个队列最多有N!种可能性。每一种可能都会导致RenderTexuture的切换次数变化,而RT的切换会在*端影响渲染性能(这是由*芯片的硬件设计导致)。所以我们必须找一个一条RT切换最少的队列。要完成这个我们需要遍历所有可能性,这时我们面临一个问题,就是在N!的复杂度下,当节点过多时,计算变的不可能完成。我们测试当节点到达30个时,基本需要几个小时了。而如果再多加一个,很可能需要几天。而我们希望是要100个以应对未来和PC上的需求。 RenderGraph的解决:这里我试图在编译节点剔除掉一些可以被忽略的节点,但是在测试当前最复杂的图时,依然非常吃力。所以我跳出现有思维,在一篇GDC的文章启发下,我找到了用基因算法去解决这个问题。基因算法是一个相对成熟的AI算法,可以解决在海量不可计算的情况下,找到一个相对的最优解。所以我先用拓扑遍历得到M条可能的序列,在满足现有依赖关系的情况下,将现有的队列两两配对,完成了两条序列的杂交和变异。在得到的新的队列和原有的队列中找到cost最少M条队列。然后重复迭代。在迭代K=100代的时候,基本可以找到一个不错的方案。这里的M和K的参数越大,结果越好。在这种算法下,40个节点的图基本在毫秒界别就能完成计算,即使扩展到100个,也能在几秒内完成计算。 RenderTexture的管理:在运行阶段,我们需要为每个feature分配RT,项目曾今用静态的方式去处理这个问题,结果是RT过大,因为很多情况下RT是可以复用,比如featureA已经执行完毕,它的临时RT已经不再使用,这张RT可以被具有相同的参数的featureB使用。我在处理这个问题时,用了一个RT的缓存池子,并根据RT的参数去生成一个HashCode(该算法在Unity源码中大量使用,用于区分对象是否发生改变),用这个HashCode做为Key去缓存池申请RT。这样就可以实现最大限度的优化RT,且因为全局唯一,所以不同的view下的RenderGraph可以共享使用。 日志:在RenderGraph开发阶段,我们会面临一个问题,就是调试异常麻烦,特别RT被设置错误时,效果出错且没有任何报错和异常的日志。所以我们并不能借助Unity FrameDebug和RenderDoc去定位我们开发的RenderGraph对应的管线的问题。因此我在管线中加了大量的日志,通过不同的类型记录不同的参数(该做法参考Unity的日志系统),该功能虽然代码里巨大,但是最终我会得到一份管线详细的数据,包括各个feature的执行顺序,RT使用情况,Load/Store Action参数,甚至到每个SRP API的调用。最终这个日志可以大大提高现有代码的调试且可以提供一份详细的数据记录,未来可以生成一份可视化的调试工具,类似FrameDebug。
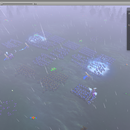
这是一个实时战斗的战争玩法,小兵的数量我们计划是1000个单位,多兵种,每个兵种有自己特有的AI和技能。这个玩法类似莉莉丝的《剑与家园》。我在该玩法的开发中完成超过90%的功能,主要涉及基础框架代码,兵种AI,技能和buffer以及相关的性能优化。 基础框架: 主要包含项目开发的通用模块,Unity Asset的加载和释放的管理,网络,UI的管理以及相关规范制定,缓存的管理方案以及一些规范类的文档编写。 AI: AI部分就是小兵的寻路部分,这部分的性能消耗最大的是物理碰撞和寻路算法。因为要做录像功能,所以我们不能使用Unity自带的寻路和碰撞。一方面是两部分因为API的原因很难集成到我们逻辑计算里,另一方面它们的运算都是基于浮点数,在播放录像时会出现结果不稳定的情况。所以我自己单独实现了一套圆形的碰撞而技术核心是用四叉树就解决碰撞的性能问题。另一方用跳点算法代替A星算法加速了寻路速度。而AI部分我们则是用阵型AI叠加小兵单独AI的模式,避免了N*N的算法复杂度。最后我们实现了一套通用的AI和扩展了每套小兵可能有的独立AI。 技能和buffer: 技能这块主要是一些编程技巧,我将技能需要的指令原子化,比如移动,等待时间,造成一次伤害,添加buff等。然后再实现一套定时器(原因也是录像功能),将定时器和指令结合生成一个技能管理器和buff管理器,用来定时触发指令。buffer还会有自己独立的触发时机。因为编程部分已经实现指令化,所以我再实现了配置表处理一些通用技能的同时,又将指令封装成API对接Lua后,可以用相对Lua快速的开发。但是我们没有实现编辑器是因为开发周期不允许,各自个人是有一套这套编辑的构想。 CPU性能优化: 因为是CPU计算非常密集的玩法,所以数据结构上我没有使用List而是直接使用Array,尽量避免Dictionary。避免使用C#的语法糖,比如foreach等。一开始我会尽量去优化寻路算法,用缓冲池管理单帧的寻路次数。但是这样在大量数量的小兵时,会出现很多小兵“发呆的情况”。后来我用多线程去解决这个问题,但是因为需要实现录像功能,所以这里会有些限制且需要两套完全独立的数据在主线程和子线程。首先我将计算量最大的AI放到子线程,限定每0.5秒一个回合,每回合向子线程请求一次AI计算,等计算完毕返回后,开始计算技能(这里不一起放到子线程是因为节能对接了Lua,Lua是单线程的),然后开始表现。这里为了解决多份数据的问题,我单独生成了一份表现数据,用来在主线来做图像的表现(该数据类似: A模型做一个Idle动作,A模型从a位置移动到b位置等)。这样主线程只负责表现,而表现数据的生成则有子线程的AI和主线程技能完成。 GPU性能优化: 这部分的优化主要来自绘制1000单位的压力。正常我们直接使用Unity自带的Animator的话,基本300个就卡的不行了,原因是模型的动画计算已经将CPU卡死。所以我们想到将动画计算移动到GPU上。为了降低实现的复杂度,我们最终没有完成蒙皮的移植,原因是小兵太小确实也不需要,而针对首领这样的大型单位我们直接使用Animator,数量也不多。所以我们将动画部分的数据记录到贴图上,然后使用GPU Instance去实现大量小兵的绘制,绘制的数据来自于战斗本身的小兵的数据和表现数据(位置,模型ID,当前动画等)。 文档规范的编写: 这部分主要是为了规范资源命名和工作流程。





