

0
1
2
3
4
5
0
1
2
3
4
5

 ********
******** ********
********2018-03-01 -至今华研数据Python
为民众提供股票公司相关的舆情信息, 包含资讯、研报、 公告、自媒体、股票数据等相关数据和工具 技术要点:Scrapy(舆情资讯爬取) + Requests(股票数据爬取) + Mysql(股票历史数据存取) + Flask(华研头条核心内容接口) + ElasticSearch(舆情数据存取、搜索、数据分析) + Mongo(舆情数据备份、带标签的文章、股票数据存取 和 头条一些网站数据、金融数据和统计结果存取) + Redis(缓存) + Neo4j 责任描述: 1. Scrapy框架建立舆情新闻爬虫基础设施, 设立字段规范,负责爬虫爬取决策和方案(后期有其他同事专门写爬虫); 2. Requests 爬取公司股票的交易信息,金融数据, 存入mysql或者mongo; 3. 利用ElasticSearch系统进行舆情新闻预分类和缓存,还有舆情分析(文章每日数量, 热门作者等) 4. Flask 框架建立爬虫舆情系统的核心内容接口,包括股票、 舆情文章、数据分析结果、搜索功能、用户关注作者和通知等接口; 5. Redis用于缓存和临时数据存取, Neo4j存取公司数据和关系
2011-09-01 - 2015-09-01太原理工大学计算机科学与技术本科
热爱互联网 学习能力强 英文阅读能力优秀 有过组织领导经历 有耐心,愿意与同事沟通 性格开朗幽默
爬取腾讯视频指定视频的弹幕信息, 并保存在表格里面 使用的技术是 requests + xlml + openpyxl 先浏览器f12查找接口, 分析接口的规律, 发现接口是由视频id 和 起始终止时间 为依据请求弹幕数据的 然后循环请求所有弹幕分类存入xlsx文件
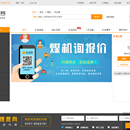
做全国煤机行业一站式采购平台先行者 矿宝网 技术要点:Django + MySQL + Whoosh + Haystack + jieba + HTML + CSS + JQ + Ajax 责任描述: 1. 设计用户信息模型、商品信息模型; 2. 用户注册对用户信息校验,并对密码进行加密存储; 3. 登录成功后对 cookie 和 session 处理,以及对页面的追踪跳转; 4. 通过装饰器判断用户登录状态; 5. 实现商品的展示,商品的分页,以及对客户最近浏览的保存; 6. 使用 whoosh 引擎和 jieba 词库实现了商品关键词检索功能;
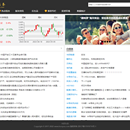
为民众提供股票公司相关的舆情信息, 包含资讯、研报、 公告、自媒体、股票数据等相关数据和工具 技术要点:Scrapy(舆情资讯爬取) + Requests(股票数据爬取) + Mysql(股票历史数据存取) + Flask(华研头条核心内容接口) + ElasticSearch(舆情数据存取、搜索、数据分析) + Mongo(舆情数据备份、带标签的文章、股票数据存取 和 头条一些网站数据、金融数据和统计结果存取) + Redis(缓存) + Neo4j 责任描述: 1. Scrapy框架建立舆情新闻爬虫基础设施, 设立字段规范,负责爬虫爬取决策和方案(后期有其他同事专门写爬虫); 2. Requests 爬取公司股票的交易信息,金融数据, 存入mysql或者mongo; 3. 利用ElasticSearch系统进行舆情新闻预分类和缓存,还有舆情分析(文章每日数量, 热门作者等) 4. Flask 框架建立爬虫舆情系统的核心内容接口,包括股票、 舆情文章、数据分析结果、搜索功能、用户关注作者和通知等接口; 5. Redis用于缓存和临时数据存取, Neo4j存取公司数据和关系






