

0
1
2
3
4
5
0
1
2
3
4
5

 ********
******** ********
********2018-02-01 -至今凯声文化高级运维工程师
1. 基础服务可靠性保证:针对业务特点部署高可用基础服务,系统层面针对性优化,添加相应监控以及告警通知,制定备份恢复方案以及扩缩方案 2. 效能提升:辅助其他团队提升工作效率,提供快速发布工具,日志查询工具,监控工具,自动化脚本等... 3. 服务监控报警:提前发现问题,及时感知突发问题,快速定位问题 4. 日常运维:处理其他团队的临时需求,基础服务的日常维护,告警问题处理等 5. 团队内部技术指导
2019-03-01 - 2021-09-02中国石油大学计算机科学与技术本科
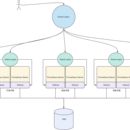
1. 在每个k8s集群中利用prometheus operator方式部署双副本prometheus+thanos sidecar,thanos sideca r一方面暴露查询接口给thanos query,另一方面上传监控数据到S3存储长期保存 2. 在各个k8s集群中部署thanos query连接prometheus服务 3.部署高性能thanos query连接各个k8s集群中部署thanos query以及s3存储作为统一查询入口 4.部署thanos ruler通过kustomize方式快速发布发布rule规则 5.容器服务采用serviceMonitor+annotations注解方式自动注册,容器外服务采用consul自动注册 6.开发webhook支持飞书,*等告警方式,其中飞书通知方式为消息卡片可以进行交互告警信息
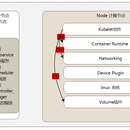
1. 制定业务接入k8s规范 2. 制定并部署K8S高可用集群,采用kubesphere进行集群管理 3. 开发K8S pipeline上线流程,实现java,nodejs,python等业务自动发布到k8s 4. k8s监控,使用thanos+prometheus operater进行容器状态监控,使用node-problem-detector进行node 节点的状态监控, 通过kube-event收集监控集群事件 5. 通过descheduler自动调度高负载节点容器到其他节点已保证各个节点资源使用的平衡 6. 通过keda自动扩容容器,可做好定时扩缩,根据内存cpu扩缩等功能 7. 通过阿里云"运维编排"实现node节点的弹性扩缩
升运维管理基础资源的效率,包括新增、销毁、关服、重启和监控等,做到流程自动化同时在此基础上扩展自动化功能等 1,权限为RBAC模式,认证采用SESSION+TOKEN,session数据存储于redis中,多节点登陆保证会话一致 2,自动上线功能开发: 2.1, 通过celery异步执行编译任务 3,监控展示包括:主机层面,Mysql,Redis,Mongo,API 数据来源包括:zabbix、阿里云、elasticsearch





