

0
1
2
3
4
5
0
1
2
3
4
5

 ********
******** ********
********APP扫码和程序员直接沟通
该用户选择隐藏工作经历信息,如需查看详细信息,可点击右上角“和TA聊一聊”查看
APP扫码和程序员直接沟通
该用户选择隐藏教育经历信息,如需查看详细信息,可点击右上角“和TA聊一聊”查看
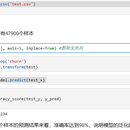
项目名称:基于XGBOOST的客户流失预测模型 1. 功能模块: - 数据探索:通过对训练数据集的分析和可视化,了解数据的特征和分布情况。 - 数据预处理:对数据进行清洗、缺失值处理、特征工程等操作,以准备好输入模型的数据。 - 模型训练:使用XGBOOST算法构建分类模型,并利用随机过采样方法平衡样本分布。 - 模型评估:通过交叉验证等方法评估训练模型的性能和准确率。 - 测试和预测:使用测试数据集对训练好的模型进行验证,并预测新数据的流失情况。 - 结果展示:通过绘制准确率曲线和特征重要性图表,展示模型的性能和关键特征。 使用者可以通过该项目实现以下功能: - 对客户流失数据进行探索性分析,揭示数据的特征和趋势。 - 运用XGBOOST算法构建客户流失预测模型,从而评估哪些客户有可能流失。 - 对新数据进行预测,并根据模型结果提出相应的策略和措施,以减少客户流失率。 2. 任务和技术栈: - 我负责完成整个项目的设计、开发和测试工作,以实现客户流失预测模型。 - 技术栈包括Python编程语言和以下关键库:pandas、matplotlib、xgboost、scikit-learn、imblearn。 - 利用pandas库进行数据读取和预处理,matplotlib库进行数据可视化。 - 使用xgboost库构建分类模型,并通过随机过采样方法平衡样本分布。 - 利用scikit-learn库进行特征标准化、模型训练和评估。 - 最终的成果是一个基于XGBOOST的客户流失预测模型,能够在给定数据集上进行流失预测,并提供模型准确率和特征重要性分析。 3. 难点和解决方案(选填): - 难点:样本不平衡问题。在客户流失预测中,正负样本的分布通常不平衡,容易导致模型学习偏向多数类别,准确率降低。 - 解决方案:使用随机过采样方法(RandomOverSampler)平衡样本分布,增加少数类样本的数量,从而提高模型对少数类的学习能力。 - 另外,也可以尝试其他方法如欠采样、SMOTE等来平衡样本分布,或者使用类别权重调整(class_weight)来加权处理不平衡样本。
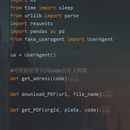
1.功能模块和实现功能: 爬取巨潮资讯年报:通过输入股票代码,自动从巨潮资讯网站爬取该股票对应的年报PDF文件。 PDF文件下载:将爬取到的年报PDF文件保存到本地指定的文件夹中。 对于使用者来说,该项目可以方便地获取股票对应的年报文件,帮助用户快速有效地获取财务信息和公司公告等重要资料。 2.我的任务和技术栈: 我负责开发整个项目的设计和实现。 使用的技术栈包括Python编程语言和相关的库和框架,如requests、pandas、json等。 通过构建请求URL、发送HTTP请求、解析返回的JSON数据以及使用文件操作函数等技术,实现了从巨潮资讯网站爬取年报PDF文件并保存到本地的功能。 最终的成果是一个可靠、高效的爬虫工具,能够根据股票代码自动获取对应的年报PDF文件。 3.难点和解决方案(选填): 在爬取巨潮资讯网站时,可能会遇到请求被拦截、数据解析不正确等问题。为了解决这些问题,我采取了如下措施: 通过设置请求头信息,模拟真实的浏览器请求,降低被拦截的概率。 在解析返回的JSON数据时,针对特定条件(如标题中包含特定关键词)进行过滤,以提取出符合要求的年报数据。 控制请求的频率,添加适当的延时,避免对目标网站造成过大的访问压力
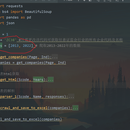
项目介绍: 1.功能模块及使用者功能: 数据爬取模块:根据用户指定的日期和行业代码,爬取新浪财经证券会行业企业的资产负债表、利润表和现金流量表数据,并保存为Excel文件。 数据解析模块:解析爬取的报表数据,提取科目名称和对应的金额,并按照日期和科目分别保存在不同的数据表中。 数据合并模块:将解析后的数据合并为一个完整的数据表,并保存为Excel文件。 使用者能够通过输入指定的日期和行业代码,快速获取该行业企业的财务报表数据,并灵活地进行数据分析和比较,以支持决策和投资。 我负责的任务、技术栈及成果: 我负责开发了数据爬取模块和数据解析模块。在数据爬取模块中,我使用Python编程语言,结合requests库和BeautifulSoup库,实现了爬取新浪财经网站的数据功能。在数据解析模块中,我使用BeautifulSoup库解析爬取的HTML代码,并根据报表的结构,提取出科目名称和金额数据。 我还使用了Pandas库来处理和合并数据,并将解析后的数据保存为Excel文件。通过数据的整理和合并,最终实现了一个完整的财务报表数据爬取和保存的功能。 这样的技术栈选择和开发工作,最终实现了一个方便用户获取并分析财务报表数据的工具。用户可以根据自己的需求,灵活地选择日期和行业代码,获取目标行业企业的财务数据,并进行后续的数据分析和决策。 难点及解决方案: 难点:解析不同公司的财务报表数据的结构可能不同,需要适应不同的HTML结构。 解决方案:通过分析不同公司报表的HTML结构,灵活地编写解析代码,以适应不同的情况。使用BeautifulSoup库提供的强大的选择器功能,可以根据报表的特定元素和属性,准确地提取所需的数据。 难点:大量爬取和解析数据可能导致网络请求过多或性能下降。 解决方案:为了避免造成负担,使用合适的爬取速率,并对请求进行合理的控制和优化。另外,对于大量数据的解析和处理,可以使用并行处理或分批处理的方式来提高效率。





